
2024年08月07日
JENNIFER
インテリジェンス運用法
目次
1.異常値の検知
JENNIFERは障害原因の多様なエラーに対してエラーイベントを提供します。異常値の検知は急激な負荷で性能低下を検知するために設計されました。下記のようにメトリクスが信頼区間の上限または下限を逸脱すると、アラートを発出します。
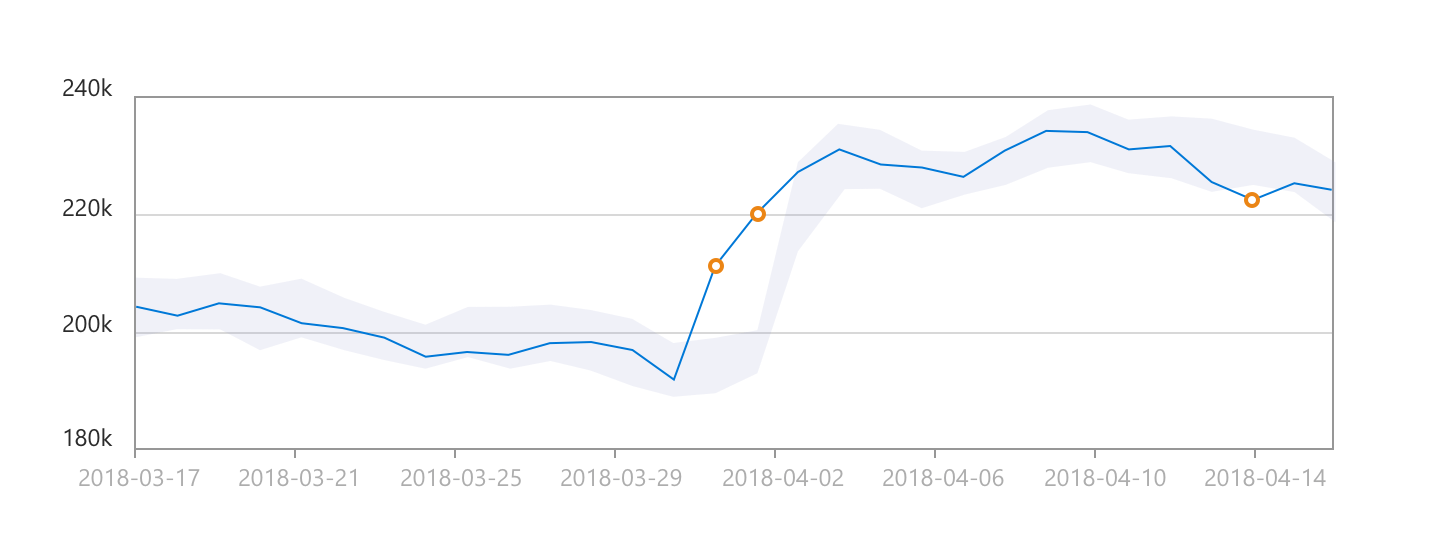
<信頼区間>

1.1.異常値の検知時点
異常値の検知イベント発生の有無は性能を考慮して周期的に決定します。この周期は測定時間です。下の図は前の測定時点、現在の測定時点、次の測定時点間の異常値の検知過程を表します。

a. 現在の測定時点を基準に前の測定時点~現在の測定時点までの異常値の検知の有無を計算します。
b. 個別の時点を基準にウィンドウ(w)の区間に対してメトリクスの平均(m)と標準偏差(s)を計算して信頼区間の計算に活用します。
c. 信頼区間を逸脱すると、その継続時間の設定値でイベント発生の有無を決定します。
d. イベント発生時、他のイベントと同様にその深刻度でアイコンの色が決められて、次の測定時間で元に戻ります。従って、アイコン自動復元の時間は測定時間と同じです。
1.2.信頼区間の計算
信頼区間は統計的なモデルを基に多数のアラートが発生しないように3-σ(シグマ)規則※1に基づいて下記のように計算します。

a. 特定時点tにメトリクスmのウィンドウwに対する移動平均、標準偏差は次のように計算します。
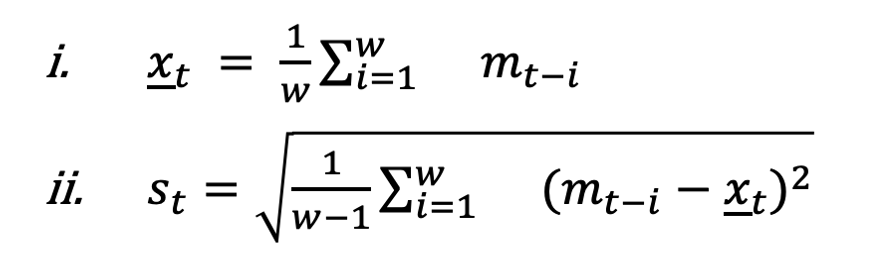
b. 上記の値の元づいた信頼区間の上限、下限は次のように決定します。このときcは安定的な指標に対して最少信頼区間の幅を指定するための定数です。

2.時系列の予測
JENNIFERでは「予測」には基本的に不正確な要素が含まれているため、保守的なアプローチをしました。一部のチャートで下記のような昨日の値と比較する機能のみをサポートしています。




24時間チャートで昨日の値との比較結果が「予測」のように見えるため、その差が発生したとき、信頼性に問題があります。また、昨日のデータを単純表記するため、曜日別、月別パターンが存在する場合、実際の値と差が大きくなります。そのため、時系列予測機能は保守的なアプローチを維持しますが、昨日の値以外にも使える曜日別、月別パターンのデータがあれば、それを活用して実際の値と差が大きくなる現象を減らすように設計しました。
2.1.時系列予測の対象
JENNIFERがモニタリングするメトリクスは非常に多様で全ての値をリアルタイムに予測することは非効率です。従って、ユーザビリティを考慮して24時間チャートに対してのみ選別的に予測を行います。これは、時系列予測対象のチャートは既存のリアルタイムダッシュボードとユーザ定義ダッシュボードに含まれたチャートであるために、ユーザが追加設定しなくても精度の向上した予測結果を得ることができます。
2.2.時系列予測の方法
具体的な時系列予測の方法では類似度に基づいたkNN回帰(k近傍法:k Nearest Neighbor)を使用します。これは顧客毎の曜日別、日付別データ特性が異なる点に着目したことで、オンプレミス環境でも実運用環境に適合した予測値を自動的に生成します。
a. 過去24時間の日単位データを収集する。データ収取は5分単位の値を基にして、一日分の長さの過去の時系列をpとすると、pは288個のポイントのデータで作られた配列です。

b. 曜日別、月別パターン適用のため、データの可用性とビューサーバの状況により、最小2日(1日、7日前)、最大20日(1~10日、25~35日前)のデータを候補の集合としてローディングしてPで表記します。
c. 性能低下を減少させるため、日単位データを次のようにフィルタリングします。今日の時系列をqとすると、現在の時点tを基準にt+1時点のp値が上下10%の範囲内に存在する時系列のみ次のステップの類似度計算に適用します。

d. 類似度は現在の時点tで二つの時系列のPとQの間のユークリッド距離で計算します。

e. kは最も類似する時系列の数を表す定数で、wはk個の時系列類似度sim(p(i),q)の正規化された加重値です。このときp(i)類似度が高いi個目時系列を意味します。最終的に、t時点の予測値は類似時系列間の加重値の合計で生成します。


5分単位の値を活用すると、1時間当たりで12個、1日にすると12 * 24 = 288個となります。
3.X-Viewパターンの認識
JENNIFERではX-Viewはモニタリングの革新的なコンポーネントです。X-Viewの多様な応答パターンに対する原因分析の関連資料を提供しています。しかし、経験が浅いユーザはこのようなパターンを認識することは簡単ではないため、性能低下を伴う典型的なパターンを認識できる機能を提供しています。
3.1.認識対象のパターン
a. 注意パターン:システムの問題があるため、原因を分析して解決することが必要なパターン。横線が発生している時はタイムアウトが存在するか、縦線が発生している時はリソースのロックが発生しているかを確認する必要があります。

b. 参照パターン:休憩パターン、正常パターンは一般的なシステムで発生することがあります。カオスパターンの場合、パターンだけでは問題を解決できないため、応答時間が長いトランザクションから分析する必要があります。

3.2.パターン認識方法
パターンを分類するディープラーニング(深層学習)モデルはイメージ分類に適合することで知られたCNN(Convolutional Neural Network)モデルを基盤に動作します。

ディープラーニングモデルの最後のレイヤーはsoftmax関数による確率生成レイヤーで構成されています。従って、モデルの結果は認識の対象になる9個のパターンに対する確率を含めたベクトルで表されます。この中で最も高い確率を表すi個目のパターンが結果パターンになります。結果パターンの確率が50%を超える場合はX-Viewがその旨のメッセージを提供します。
3.3.ディープラーニングモデルの活用
一般的にディープラーニングモデルの学習と推論は別途のGPUを備えたマシンをオンプレミス環境で追加するか、データをクラウドへ送るなどの環境を分離する方式で導入します。しかし、実運用時には学習されたモデルを推論するのに大量のリソースは必要ないために、JENNIFERが動作するEdgeマシンのブラウザで直接推論を実行する方法で、追加費用なくオンプレミス環境でもディープラーニングモデルを動作できるように設計しました。

- 顧客外部のマシンで認識したい学習データを生成させます。
- 学習データを基にしたディープラーニングモデルを学習させます。
- 学習させたディープラーニングモデルを別のファイルサーバに配布します。
- JENNIFERでファイルサーバにアクセスして学習させたディープラーニングモデルをダウンロードしてブラウザでローディングします。
- ブラウザはX-Viewのパターンを全て比較し、ディープラーニングモデルの結果をローカルで実行します。
このようなプロセスを経てJENNIFERがモニタリング中のサーバとJENNIFERを運用中のサーバに負荷を与えずに、リアルタイムでパターンを分類することができます。
4.類似アプリケーションの照会
JENNIFERのアプリケーションサービスは性能モニタリングで重要であるため、詳細な分析が必要です。次の図では、アプリケーション別に類似するパターンを色付けしてグループ化できることを確認できます。特に、右下のグループは共通で横線が表れますが、タイムアウトと関連した問題点があることが予想できます。

このような観察に基づいて、類似アプリケーション照会機能はアプリケーション別に類似度を計算して、類似するパターンのアプリケーションを一緒に分析、改善できるように設計しました。
4.1.類似アプリケーションの計算方法
アプリケーションの類似度は該当時間での応答パターン間の類似度で定義します。応答パターン間の類似度は統計値で計算されます。下記の図でアプリケーション応答パターンはX-Viewの横軸を基準にW個の区間に分かれます。

a. システムは各区間でmax、min、avg、cntのそれぞれの統計値を抽出して、各統計値別に長さWの時系列を四つ生成します。これは全てのアプリケーションに対して計算します。アプリケーションをpと表記すると各時系列はp_max、p_min、p_avg、p_cntと表記できます。
b. 二つのアプリケーションpとqの類似度は各時系列の類似度に対して加重値の合計で決定します。つまり、二つの時系列間の類似度関数をs1とするとs1(p_max,q_max)、…、s1(p_cnt,q_cnt)ペアの各類似度を求めて、更に各統計値の重要度を決定する経験的定数w_max、…、w_cnt値を各々掛け算して最終類似度を決定します。
c. ここでwは0~1の間の値で、各統計値に対する加重値の合計は1です。

d. 二つの時系列pとq間の類似度関数s1は、i個目の区間で時系列の値のpiとqi間の類似度平均で表されます。piとqiの類似度を求める関数s2は次の通りです。

すなわち、特定区間でpとqの値が同じであれば区間類似度s2の値は1です。二つの値が異なる場合は二つの中で小さい値を二つの値の平均で割り算した値になります。これにより、類似度の値を0~1の間の値に制限できます。二つの値が近いほど1に近い値になります。
※1平均から3-シグマ(標準偏差)間に99.73%の値が含まれるという統計的な仮説です。多様なドメインで経験的に正確性が認められ、性能低下の要素が少ないため、異常値検知の基本に使用します。