
2024年07月09日
連載 第8回
Karpenterによる
ノードオートスケール

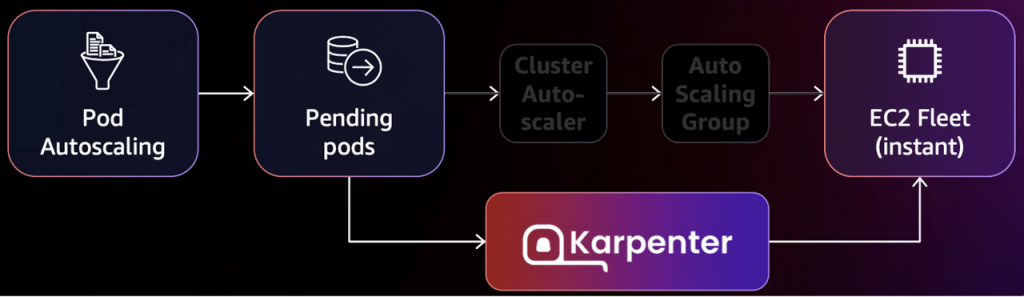
今回はノードオートスケールを確認します。
クラウド環境ではオンプレミス環境に比べて、ワーカーノード(VMインスタンス)の拡張と縮小が簡単です。クバネティスを使用する前にVM環境でAWSのオートスケールを使用し、システム負荷に応じて柔軟にEC2リソースを使用したように、クバネティス環境でもワーカーノードを自由に拡張と縮小ができます。
クバネティス環境でノードオートスケールはCluster AutoScaler(CAS)とKarpenterで使用できます。Karpenterは既存のCASに比べて構造が簡単なため、より速く柔軟です。ノードコストもCASに比べて節約できます。実習を通して詳細にKarpenterを確認します。
主な内容:
- CAS(Cluster AutoScaler) とKarpenterの比較
- Karpenterのメリット
実習課題:
- Karpenterとeks-node-viewerのインストール
- Karpenterを利用したEKSノードスケールアウトとスケールインのテスト
今回の実習で使用するソースファイルのGitHubディレクトリは次の通りです。
1. Cluster AutoScalerとKarpenterの比較
KarpenterはKubernetesクラスタでノード管理とスケールを最適化するためのオープンソースです。従来はCluster AutoScaler(CAS)を使用して、クバネティスノードのスケールを動的に変更しました。CASは各クラウドサービスベンダー(AWS、Azure、GCP)に適合した別のAPIを利用します。
CASはAWSのAuto Scaling Group (ASG)を利用してEKSのノードを管理します。ASGはEKSと関係のない別のAWSリソースで、ASGとEKSノード間のデータの同期化作業が必要で、追加の時間がかかります。テストをするとノードの増設にCASは約2分かかりましたが、Karpenterは40秒でした。
AGSノードグループは単一インスタンスタイプしか使用できず、リソースを浪費することがあります。例えば0.1Core/128Miリソースを使用する一つのPodのみを実行する時に、4Core/32Giのリソースを持つノードが必要なため、コストを浪費します。
CASはKarpenterに比べて先に開発され、技術的に成熟していますが、コストと速度の面ではKarpenterが優れています。最近では多くの企業がKarpenterを導入しています。筆者も Karpenterを導入することで、従来と比べて30%以上のコストを節減できました。

Karpenterは ASGを使用せず、EKSノードを直接増加したり、減少したりします。また、Podのリソース使用量が最も少ないノードを自動で割当てます。さらに、実行中のPodが終了すると、再度必要なリソース使用量を確認し、必要により自動でコスト最適化のために既存ノードを削除し、新しい最適なノードを割当てます。
しかし、Karpenterを使用するためにはノードの最適化の時に、新しいノードが実行され、既存ノードは終了するため、実行中のPodは終了させて新しく実行するPodの二重化、PodDistributionBudget、Graceful Shutdownなどのサービス安定化のための基本設定作業が必要です。このような作業はシステムの安定性を向上させるための基本作業であるため、Karpenterと関係ないですが、必要な作業です。
2. Karpent helmのインストール
Karpenterをインストールして詳細に機能を確認します。KarpenterはEKS外部のEC2インスタンスを制御するためIRSAが必要です。TerraformのKarpenterモジュールの利用は、インストールの時に便利です。既存のEKSのインストール時に使用したコードに下記のようにKarpenterモジュールを追加します。
Terraform karpenter モジュール
1. module "karpenter" {
2. source = "terraform-aws-modules/eks/aws//modules/karpenter"
3.
4. cluster_name = module.eks.cluster_name
5. irsa_oidc_provider_arn = module.eks.oidc_provider_arn
6.
7. policies = {
8. AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
9. }
10.
11. tags = local.tags
12. }次に、Terraformを利用して配布します。
$ (⎈ |switch-singapore-test:default) tf init
$ (⎈ |switch-singapore-test:default) tf plan -out planfile
$ (⎈ |switch-singapore-test:default) tf apply planfile
注意事項は、Terraformコードを実行すると生成されるOutputの下記のKarpenter部分を記録することです。これはKarpenter helmのインストールに必要な ‘karpenter_instance_profile_arn’ と ‘karpenter_queue_name’ の情報です。
1. karpenter_instance_profile_name = "Karpenter-jerry-test-2023082121003044240000001d"
2. karpenter_queue_name = "Karpenter-jerry-test"IRSAの設定が完了したら、次はKarpenterをインストールします。これもhelmを使用します。
1. $ (⎈ |sent-seoul-stage:mongodb) helm pull oci://public.ecr.aws/karpenter/karpenter --version v0.27.5
2. Pulled: public.ecr.aws/karpenter/karpenter:v0.27.5
3. Digest: sha256:9491ba645592ab9485ca8ce13f53193826044522981d75975897d229b877d4c2
4.
5. $ (⎈ |sent-seoul-stage:mongodb) rm -rf karpenter-v0.27.5.tgz
6. $ (⎈ |sent-seoul-stage:mongodb) mv karpenter karpenter-v0.27.5
7. $ (⎈ |switch-singapore-test:echoserver) cd karpenter-v0.27.5
8. $ (⎈ |switch-singapore-test:echoserver) cp values.yaml my-values.yamlデフォルトhelm Valueファイルを下記のように変更します。
my-values.yaml
1. replicas: 2
2.
3. controller:
4. resources:
5. limits:
6. memory: 1Gi
7. requests:
8. cpu: 100m
9. memory: 1Gi
10.
11. serviceAccount:
12. annotations:
13. eks.amazonaws.com/role-arn: $ROLE_ARN
14.
15. settings:
16. aws:
17. clusterEndpoint: $Endpoint
18. clusterName: $Name
19. defaultInstanceProfile: Karpenter-jerry-test-2023082121003044240000001d
20. interruptionQueueName: Karpenter-jerry-test. serviceAccount.annotations.eks.amazonaws.com/role-arn: $ROLE_ARN
前で生成したTerraform KarpenterモジュールのKarpenter ROLE_ARN情報を入力します。
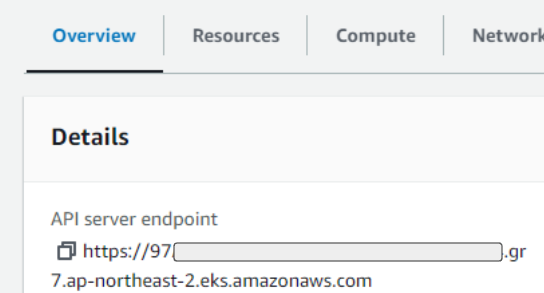
. settings.aws.clusterEndpoint
clusterのAPI サーバのEndpoint情報を入力します。EndPoint情報はAWS EKSコンソールで確認できます。
. settings.aws.defaultInstanceProfile, interruptionQueueName
前でインストールしたTerraform Karpenterモジュールのアウトプットの結果を入力します。
次に、Karpenterネームスペースにインストールします。
1. $ (⎈ |switch-singapore-test:karpenter) helm install karpenter --namespace karpenter --create-namespace -f my-values.yaml .
2. NAME: karpenter
3. LAST DEPLOYED: Fri Sep 22 05:51:10 2023
4. NAMESPACE: karpenter
5. STATUS: deployed
6. REVISION: 1
7. TEST SUITE: Noneインストールが完了するとKarpenter Controller Podをkarpenterネームスペースで確認できます。
1. $ (⎈ |switch-singapore-test:karpenter) k get pod
2. NAME READY STATUS RESTARTS AGE
3. karpenter-f654d4b8d-v65dk 1/1 Running 0 7d13h3. KarpenterプロビジョナーとAWSノードテンプレートのインストール
Karpenterが新しいノードを配布するためにノードの設定が必要です。Karpenterはプロビジョナー(Provisioner)とAWSノードテンプレート(NodeTemplate)の2つのCRD(Custom Resource Definition、ユーザ定義リソース)を利用して詳細内容を定義します。
プロビジョン(Provisioning)という用語は主にIT環境では、仮想のコンピューティングリソースを割当て、構成、管理する過程を意味します。Karpenterでも同様にクバネティスノードの物理的な要求に関する定義を含みます。どのリソース要求を満足すべきか、どの制約条件を考慮すべきかなどのポリシーが含まれます。
次のマニュフェストファイルの例で確認します。
provisioner.yaml
1. apiVersion: karpenter.sh/v1alpha5
2. kind: Provisioner
3. metadata:
4. name: spot
5. namespace: karpenter
6. spec:
7. # References cloud provider-specific custom resource, see your cloud provider specific documentation
8. providerRef:
9. name: default
10.
11. # Labels are arbitrary key-values that are applied to all nodes
12. labels:
13. env: test
14.
15. # Requirements that constrain the parameters of provisioned nodes.
16. # These requirements are combined with pod.spec.affinity.nodeAffinity rules.
17. # Operators { In, NotIn } are supported to enable including or excluding values
18. requirements:
19. - key: "karpenter.k8s.aws/instance-family"
20. operator: In
21. values: ["t3"]
22. - key: "karpenter.sh/capacity-type" # If not included, the webhook for the AWS cloud provider will default to on-demand
23. operator: In
24. values: ["spot"]
25. limits:
26. resources:
27. cpu: "100"
28. memory: "200Gi"
29.
30. # Enables consolidation which attempts to reduce cluster cost by both removing un-needed nodes and down-sizing those
31. # that can't be removed. Mutually exclusive with the ttlSecondsAfterEmpty parameter.
32. consolidation:
33. enabled: true. metadata.name: spot
タイプによりノードを区分できます。例えば、スポットノードとオンデマンドノードでノードタイプを分けることができます。スポットノードで実行するPodは、スポットノードグループに配布できるようにスケジューリングできます。
. spec.requirements.key: “karpenter.k8s.aws/instance-family”
Karpenterが配布するノードのインスタンスファミリーを指定します。実行するPodの特性によりc6i(演算処理中心)、g5(gpuノード)、r6i(メモリ処理中心)または複数のインスタンスタイプが指定できます。テスト環境のため、筆者はコストが安いt3タイプを指定しました。
参考までに、ArmシリーズのCPUを使用するt4gシリーズのインスタンスを使用すると、コストパフォーマンスが20%程度向上します。
. spec.requirements.key: “karpenter.sh/capacity-type”
オンデマンドまたはスポットインスタンスを指定します。デフォルトはオンデマンドでスポットに変更ができます。主に大きなボリュームを使用しないステートレスPodで、任意にノードが終了しても自動的にコネクションを再開できる一般のWeb基盤のアプリケーションは、スポットインスタンスを積極的に使用します。クバネティスは高可用性基盤で設計され、スポットインスタンスを使用することに適しています。多くの企業で運用環境でもスポットインスタンスを積極的に使用されています。
筆者個人はスポットインスタンスをよく使いますが、これがEKSの大きなメリットです。
. spec.requirements.consolidation.enabled: true
ノードで実行中のPodの数が減るとKarpenterが自動でノードを統合(consolidation)するか、実行中のPodを他のノードに移行してコストを節減します。CASと異なりKarpenterは新に実行するインスタンスタイプまで調整して、コストが最も安いノードに新しいPodを配布します。
次にAWSノードテンプレートマニュフェストです。ハードウェアタイプを除いたボリュームの設定、セキュリティーグループ(Security Group)、サブネット(Subnet)などのノードの実行に必要なAWSの設定を指定します。
AWSNodeTemplate
1. apiVersion: karpenter.k8s.aws/v1alpha1
2. kind: AWSNodeTemplate
3. metadata:
4. name: default
5. spec:
6. subnetSelector:
7. karpenter.sh/discovery: jerry-test
8. securityGroupSelector:
9. karpenter.sh/discovery: jerry-test
10. tags:
11. karpenter.sh/discovery: jerry-test
12. blockDeviceMappings: # (2)
13. - deviceName: /dev/xvda
14. ebs:
15. volumeSize: 100Gi
16. volumeType: gp3
17. encrypted: true
18. deleteOnTermination: true. spec.subnetSelector, securityGroupSelector
AWSNodeTemplateではSubnetと Security Group情報が必須です。ノードがどの環境で実行するのか必要な基本情報を明示します。
Karpenterは Subnet、Security Groupのタグ情報を基準にリソースを割当てます。Karpenterをインストールすると、自動的にSubnet、Security Groupにクラスタ名を基準にタグが割当てられます。
タグ情報はAWSコンソールで下記のように確認できます。
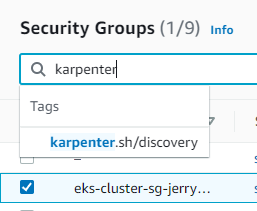
Security Group検索ウィンドウに上記のようにkarpenterを入力すると、関連リソースを確認できます。タグを確認すると上記の ‘AWSNodeTemplate’ で入力した情報と同じです。
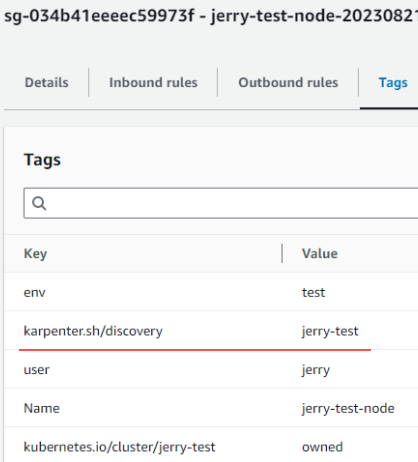
Security Groupと同様に、Subnetも同じタグを確認できます。
Karpenterが実行するノードは上記のようにkarpenterタグが指定されたSecurity Group、Subnetを割当てられます。
. spec.subnetSelector.Name: “jerry-test-private-ap-northeast-2*”
EKSノードはセキュリティーとコストの理由でPrivate Subnetグループに配布することをお勧めします。タグ名をPrivateと指定してPrivate Subnetに配布できます。
‘*’ 文法をサポートして ap-northeast-2a/2b/2cを一つずつ指定しないといけません。
. spec.blockDeviceMappings
ノードディスクの設定を変更できます。筆者は安定的に運用するためにデフォルトディスク容量を100Giと指定しました。
準備したマニュフェストを基にKarpenter CRDを生成します。
1. $ (⎈ |switch-singapore-test:karpenter) k apply -f provisioner.yaml -f awsNodeTemplate.yaml
2. provisioner.karpenter.sh/spot created
3. awsnodetemplate.karpenter.k8s.aws/default created
4.
5. $ (⎈ |switch-singapore-test:karpenter) k get provisioners.karpenter.sh
6. NAME AGE
7. spot 85s
8.
9. $ (⎈ |switch-singapore-test:karpenter) k get awsnodetemplates.karpenter.k8s.aws
10. NAME AGE
11. default 94sprovisioner、awsnodetemplateの新しく2つの CRDを確認できます。
4. Karpenter利用のノードオートスケールの実習
Karpenterが配布したノードを簡単に確認するためにeks-node-viewerをインストールします。 eks-node-viewerはAWSで開発したツールで、動的にノードの変化量を可視化するCLI基盤のツールです。brewを使用してインストールできます。
1. brew tap aws/tap
2. brew install eks-node-viewer次に、eks-node-viewerを実行します。

スクリーンショットで確認できるようにeks-node-viewerはクラスタのノード状態を直観的に表示します。インスタンスタイプ、スポット/オンデマンドの可否を表示し、コストまで確認できます。また、現在のノードのリソース割当てキャパシティ(Capacity)を実行中のPodのリソースリクエスト量(Request)に対するパーセンテージ(%)で表示します。簡単にリソースの割当てが効果的に実行されているかを確認できます。
一つ注意すべき点は実際のリソース使用量(Usage)ではなく、リソースリクエスト量を基準に3つのリソース量があります。一つは、リソース割当てキャパシティは物理的にノードが使用可能な全体のリソース量です。二つ目に、リソースリクエスト量はノードで実行中のPodのリソースリクエスト量の合計です。三つ目に、使用量は実際にPodが使用するリソース使用量ですが、リソースリクエスト量より低い場合も高い場合もあります (勿論、リミット以上は使用できません)。キャパシティのリクエスト比率(割当て量)を上げるとノードのリソースを効果的に使用できます。
また、eks-node-viewerは実ノードが配布する時間も確認できます。
では、Karpenterを利用して、新しいノードを配布し、ノードの変化をeks-node-viewerで確認します。Karpenterが Podのリソースリクエストでどのように自動でノードを増加するかを確認する実習です。実習に使用するPodのマニュフェストは次の通りです。
busybox deployment
1. apiVersion: apps/v1
2. kind: Deployment
3. metadata:
4. name: busybox
5. namespace: default
6. spec:
7. replicas: 4
8. selector:
9. matchLabels:
10. app: busybox # POD labelと一致
11. template:
12. metadata:
13. labels:
14. app: busybox # Selector labelと一致
15. spec:
16. containers:
17. - name: busybox
18. image: busybox
19. command: ["sh"]
20. args: ["-c", "sleep inf"]
21. resources:
22. requests:
23. cpu: 400m
24. memory: 128Mi. spec.template.spec.resources.requests
KarpenterはPodの CPUとメモリリクエスト量(requests)を基準に新しいノードを実行します。リクエスト量を満足するノードの中で、最もコストの低いノードを選択します。上記の例は(400m * 4、128Mi * 4)を満たすノードを実行します。
コマンドウィンドウを2つに分けて上のラインは ‘busybox’ Podを実行、下のラインは‘eks-node-viewer’ を実行します。
1. $ (⎈ |switch-singapore-test:default) k apply -f busybox-deploy.yaml
2. deployment.apps/busybox created下記のようにリアルタイムでノードが準備する時間を確認できます。新しいノードが追加されるまでの時間は40秒かかりました。既存のクラスタオートスケール(CAS)を使用すると2分以上かかりますが、CASに比べ約70%速くなりました。

ノードタイプを確認するとt3.smallです。Podが必要なリソースは(CPU 400m * 4、メモリ128Mi * 4)のため、これを満たしてコストが最も安いEC2インスタンスタイプを、Karpenter Provisionerで指定したノードグループの中から自動で選択しました。
もし、既存のクラスタオートスケールであれば、リクエスト量と関係なくノードグループに指定された単一タイプ(ex. c6i.largeなど)のみを割当てるため、コストを浪費します。
次に反対に数を減少(スケールイン)させるテストをします。同じく2つのウィンドウに分けて一つのウィンドウでPodを削除します。
1. $ (⎈ |switch-singapore-test:default) k delete deployments.apps busybox

Podを削除すると上記のスクリーンショットのように約10sでノードまで削除されます。CASに比べてかなり速いです。Karpenterは中間ステップのオートスケーリンググループ(ASG)を通さず、直接ノードを管理するので処理が速いです。
ノードの増加と減少のログはkarpenter Podで確認できます。
1. $ (⎈ |switch-singapore-test:default) k logs -n karpenter karpenter-f654d4b8d-v65dk1. 2023-05-24T00:50:00.733Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0f7c4e1e1e28aea85", "hostname": "ip-10-110-25-141.ap-southeast-1.compute.internal", "instance-type": "t3.micro", "zone": "ap-southeast-1b", "capacity-type": "spot", "capacity": {"cpu":"2","ephemeral-storage":"100Gi","memory":"947Mi","pods":"4"}}
2.
3. (省略)
4.
5. 2023-05-24T01:00:13.982Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 8 machines ip-10-110-24-178.ap-southeast-1.compute.internal/t3.micro/spot, ip-10-110-27-116.ap-southeast-1.compute.internal/t3.2xlarge/spot, ip-10-110-1-0.ap-southeast-1.compute.internal/t3.2xlarge/spot, ip-10-110-22-211.ap-southeast-1.compute.internal/t3.micro/spot, ip-10-110-17-156.ap-southeast-1.compute.internal/t3.micro/spot, ip-10-110-25-158.ap-southeast-1.compute.internal/t3.micro/spot, ip-10-110-12-187.ap-southeast-1.compute.internal/t3.2xlarge/spot, ip-10-110-25-141.ap-southeast-1.compute.internal/t3.micro/spot {"commit": "698f22f-dirty"}
6. 2023-05-24T01:00:14.052Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-10-110-24-178.ap-southeast-1.compute.internal"}
7. (省略)ログからノードの増減の状況を確認できます。実務でノードの増減に関連する問題が発生すると、KarpenterPodログを確認して原因を把握できます。
以上でKarpenterを確認しました。次回はKarpenterで安全にPodを配布できるようにterminationGracePeriodSecondsとPodDisruptionBudgetオプションを確認します。