
2023年12月14日
スタックトレースサンプリングを
利用した性能分析B
スタックトレースレコーダー
(Stacktrace Recorder)
今回のテーマはシステム全体のアプリケーション性能分析で参考となる機能をご紹介します。
個別のトランザクション分析では改善できない性能問題を解決するための、開発担当者Yさんの1日
Yさんはいつも通りAPMのログ収集サーバの業務を担当していました。すると、収集サーバのログに次のような内容が出力されて、ダッシュボードにデータが表示されないとの連絡がありました。
- server.data.2022-04-14.log:2022-04-14 15:33:04.833 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=94), finish=350/1000, wait=0, process=350
- server.data.2022-04-14.log:2022-04-14 15:33:04.990 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=94), finish=300/1000, wait=0, process=300
- server.data.2022-04-14.log:2022-04-14 15:33:08.186 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=136), finish=401/1000, wait=0, process=401
- server.data.2022-04-14.log:2022-04-14 15:33:08.701 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequestt(key=520:70,bodyLength=136), finish=294/1000, wait=0, process=294
- server.data.2022-04-14.log:2022-04-14 16:28:02.497 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=94), finish=300/1000, wait=0, process=300
内容を確認してみると各リクエストは1秒以内に処理が終わっていますが、個別処理は294msから401ms(上記のログの“process=○○○”の部分)かかっています。
Yさん:
「チョット待って..1秒もない0.x秒のリクエストに対して性能改善を行うことは簡単にできることなのか?」
前回使用したトランザクション単位に収集されたスタックトレース分析機能を利用してみます。
先ず、X-Viewチャートを確認します。

大半のトランザクションが1秒未満の時間で処理されています。X-ViewチャートのY軸を小さい時間の単位に調節して、スタックトレースで収集されたトランザクションを確認しました。

この収集サーバはWebリクエストではないTCPリクエストを処理するサーバであるため、個別トランザクションが非常に短時間で処理が終了する特徴を確認できます。しかし、トランザクション毎に収集されたスタックトレース情報では性能改善のヒントが無いので、何か方法がないのかと悩んでいました。すると、別の開発担当者がメソッド呼び出しをサンプリングする機能を思い出しました。そこで、そのオプションを活性化してログを確認しました。

この機能は上のスクリーンショットにあるように、呼び出されたメソッドのサンプリング結果をログに出力します。左側のElapsedとSelfに表示された数字の値が大きいメソッドが頻繁にまたは、長時間実効されたトランザクションであることが分かりました。特に気になるメソッドがあり、このメソッドを呼び出した部分を修正すると改善できると思われました。そこで、メソッドの呼び出す位置を探しながら、Yさんは次の様に考えました。
Yさん:
「いちいちメソッドの位置を探すのは少し面倒くさいな..。
FlameGraphで確認すれば、どこを見る必要があるか、すぐに探せると思うけど!
以前分析したサンプリング結果はテキストで残さないといけないし、探すのも面倒で覚えてもいられないし..。
このような分析機能を自分の業務だけで使うのは勿体無いな。メソッド性能分析が必要なユーザも使うといいな。
よーしー、これもJENNIFERの機能として追加しよう!」
新しいスタックトレース分析機能のための準備
個別トランザクションではなく、全てのアプリケーションにサンプリング結果を照会する必要があるため、既存とは異なりX-Viewポップアップのようなアプローチポイントが無いため、新しい分析画面が必要になります。この分析機能では、既存のログに出力するサンプリング機能のデメリットを補完するために次のような目標を作成しました。
- 1日を超える範囲でも照会速度が速いこと
- 別途の複雑な設定がなく、簡単に利用できること
- エージェントと収集サーバの性能に影響がないこと
- 探すメソッドの呼び出し関係を直観的に把握できること
また、必須構成要素として二つ選定しました。
- スタックトレース収集時点に呼び出し中だったメソッドの統計(以下、Topメソッド)
- 照会範囲から照会されたスタックトレースを基盤にしたFlameGraph
以前と異なり分析の対象になるスタックトレースの数が非常に多くなる可能性があります。というのも以前は一つのトランザクションに対するスタックトレース情報でしたが、今回は全てのアプリケーションで収集されたスタックトレース情報になるためです。
“従来の分単位や、時間単位の照会範囲の調節方法より良い方法はないのかな…?”
YさんはFlame Graphと関連する記事を探している時に次のURLを見つけました。
FlameScope(https://netflixtechblog.com/netflix-flamescope-a57ca19d47bb)
内容はFlame Graph を考案した開発担当者が開発した視覚化の方法です。 ヒートマップチャートに小さい単位の時間区間で集計されたデータを数に比例する色の濃さで表現するチャートです。 一般的なヒートマップとの違いはX軸とY軸が共に時間を表示するため、時間の流れによるパターンを表現できる点です。

上の図はFlameScopeで表現された代表的なパターンで、詳細は次のURLから確認できます。
https://www.brendangregg.com/blog/2018-11-08/flamescope-pattern-recognition.html
このグラフであれば大量のデータを照会するために範囲調節ツールとしても利用できます。もし、サンプルのようなパターンを確認できれば、アプリケーションの状態まで把握することができます。
新しい分析画面用に次の3つの項目を選定しました。パターンでアプリケーションの状態を確認できること以外に時間の流れを表すチャートであるため、必要な範囲をドラッグできます。大量のスタックトレース情報の照会範囲を設定できます。
- Flame Scope
- Top Method
- Flame Graph
各項目に対する詳細内容は分析機能で確認できます。機能名はスタックトレースレコーダー (Stacktrace Recorder)です。アプリケーションが動作するときに自動的にスタックトレース情報を記録します。予想外の状況が発生した時、常時記録されたスタック情報で原因把握に決定的な力を発揮することが期待されています。
スタックトレースレコーダーの紹介
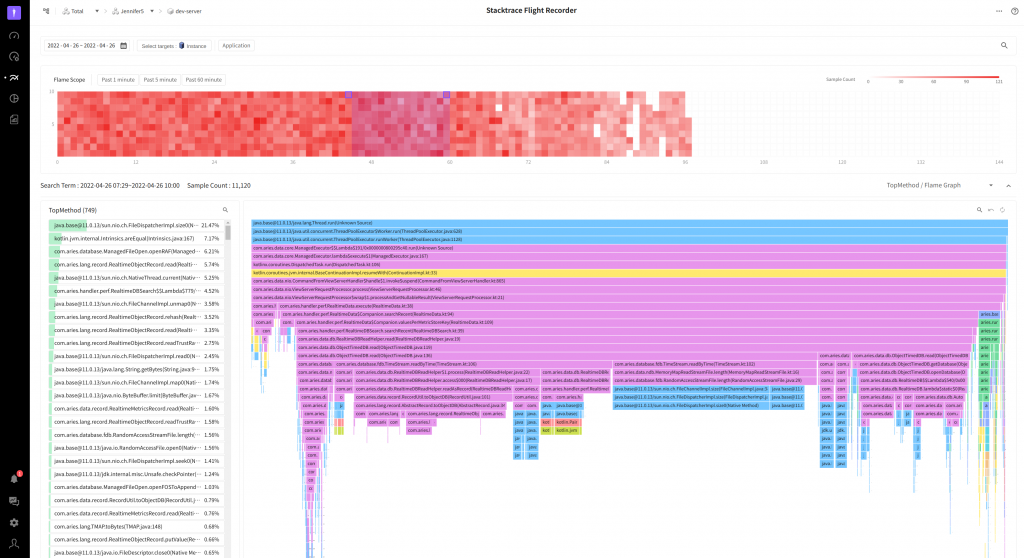
各構成要素の意図と目的
上のイメージにあるようにスタックトレースレコーダーは大きく3つの構成要素で作られています。
1. FlameScope

赤色系列の小さい四角(□)で描かれたチャートです。 各四角の一コマは1分の区間を意味します。収集されたスタックトレースの数が多ければ多いほど濃い赤で表現されます。FlameScope には2つの目的があります。
- TopMethod、FlameGraph照会範囲の選択
1日単位で照会した時の変化を確認したいため、最大照会期間は7日にしました。もし、この期間に属する全てのデータを照会すると照会時間が長くなるため、ユーザが期待するユーザビリティを満足させることはできません。濃い赤色の部分は何かの理由があって、より多くのスタックトレースが収集されたことを意味します。一般的にユーザが確認する必要があるのはこの部分です。FlameScopeを利用して分単位の収集頻度をベースに表示したため、ユーザの分析に必要な区間を狭めることができます(プロファイルを確認するX-Viewチャートと類似の機能です)。
- ヒートマップチャートに現れるパターンを基にアプリケーションの特徴と状態を予測
アプリケーションの稼働状態を表すことができます。業務中の特定時間に負荷が集中するパターン、一定の時間で周期的に実行するパターンなどを確認できます。

このスクリーンショットは特定周期で実行されるアプリケーションのパターンです。中間の白い部分はデータが収集されない区間で、アプリケーションは周期的に特定の処理を行っていることを意味します(**サービスのバックグラウンドデータ処理サーバです)。

このスクリーンショットは中間部分に他の領域より濃い赤で表示された部分(赤い四角で囲んだ部分)は午前9時から18時までの時間で、この時間帯にリクエストが集中的に発生したことを確認できます(内部デモシステムの仮想のリクエストを処理するデモサイト)。
2. TopMethod

このスクリーンショットはスタックトレースを収集した時点で実行中のメソッドの呼び出し分布を表しています。ここでユーザが作成したメソッドが上の方にあると、そのメソッドがボトルネックの可能性が高いです。スクリーンショットではファイルのサイズを測定するFileDispatcherImpl.size0メソッド(赤い四角で囲んだ部分)が最も高い頻度で呼び出されています。以前に測定したファイルのサイズをキャッシュする方法を利用すると、このメソッドの出現頻度を低く抑えることができ、その間に他のメソッドが実行できる時間を確保できることになります。これはアプリケーションの性能向上につながります。
従来のログ基盤のメソッドサンプリング分析機能を利用する時に最も有効に利用された部分で、ここで問題のメソッドを呼び出した部分を検出して改善する作業を繰り返します。しかし、一つ限界があります。問題のメソッドを探すためには、IDEを利用して呼び出すメソッド検出には相当な時間がかかります。もし、このメソッドが多くの所で呼び出される場合はかなりの負担になる作業です。(IDEが無ければおそらく不可能ですが)
3. FlameGraph

TopMethodでは退屈なメソッドの位置の検出作業から解放してくれました。ここでは既存とは異なる逆の形態のFlameGraphを利用します。
一般的にInverted Flame Graph 又は Icicle Graph と言います。上から下へ徐々に小さくなる模様がつららに似ていることで付けられた名前です。グラフの最上段はスタックトレースの開始時点で、下の方が直近に実行されたメソッドが表示されます。
もし、一般的な形態の Flame Graph を利用した場合は、低い解像度のモニターを使用するユーザでは、高い確率で細い針金のような区間(スクリーンショットで左右の赤い四角で囲んだ部分)だけしか確認できまません。この機能を初めて見たユーザはすこし戸惑うと思います(この場合はメソッド名が確認できません)。
Inverted Flame Graph を利用すると、最上段に確認できる領域は呼び出しスタックの開始時点であるため、ユーザが簡単に確認できます。また、Self メソッドは既に左側にある、Top Methodですぐに確認できる状態です。!
左側にある TopMethod の各ラインをクリックするか、検索キーワードを入力すると、該当するメソッドの位置をFlame Graphでハイライト表示するため、頻繁に呼び出されるメソッドとそのメソッドの呼び出した部分を簡単に確認できます。

既存のFlame Graphでは多くの部分が改善されました。右側上のフィルタリング(赤い四角で囲んだ部分)を設定すると、一致するメソッドを簡単に確認できます。更に各□をクリックすると、他の呼び出しツリーを除外して現在の呼び出しツリーだけを表示します。ズームイン状態を元の状態に戻し、ズームインを初期化する機能もサポートします。
ここまでスタックトレースレコーダーの各構成要素について確認しました。
次はスタックトレースレコーダーを利用して開発担当者 Yさんが経験した比較的速い応答時間のアプリケーションの性能改善にトライして、実際の効果がどの程度であるかを確認します。
問題は何でしたか?
APMダッシュボードに表示される各チャートのデータは対象別、チャートの種類別に収集され、1秒毎に保存されます。従って、モニタリング対象が多くなると照会待ち時間は遅くなります。
利用者にはモニタリング対象を適切な数に絞ることをお勧めしますが、強要することはできません。
個別の照会はどれだけ速くてもディスク I/Oと直結しているため、同時に複数の照会が行われると、大半のスレッドが処理状態になり、以降のリクエストは待機状態になります。
- 2022-03-30 00:00:03.979 [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=4258), finish=750/1000, wait=717, process=32
- 2022-03-30 00:00:04.002 [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler – Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=2098), finish=783/1000, wait=717, process=65
上のスクリーンショットでは、処理時間のprocess(1.では32ms、2.では65ms)はそれほど長くないですが、待機時間のwait(1.では717ms、2.では717ms)がかなり長いことが確認できます。Waitを短くするためには、それぞれの小さいタスクの処理時間をより短くすることで可能です。ボトルネックを正確に把握して応答時間の改善を行います。先ず、収集サーバに APM エージェントをインストールして1日で収集されたデータを照会します。

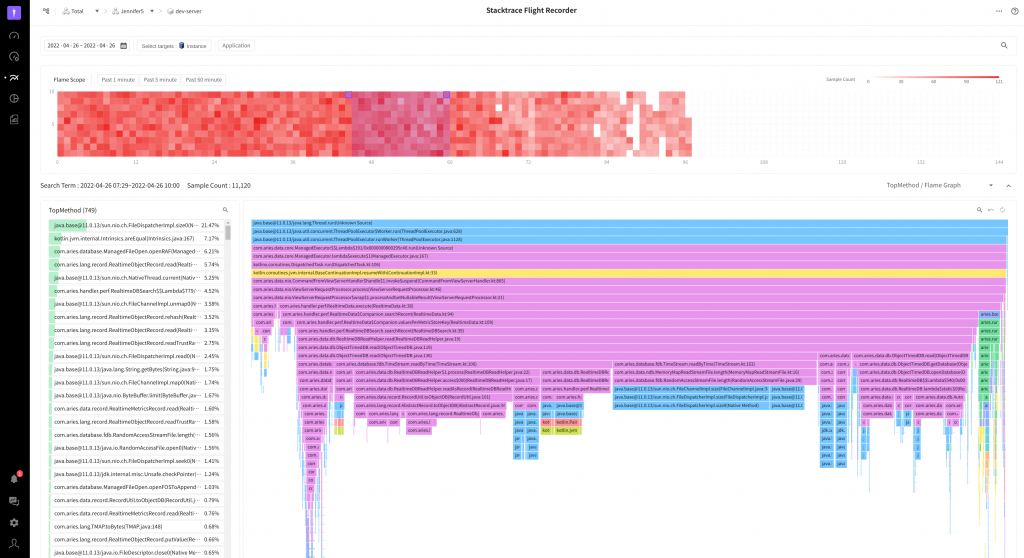
Flame Scopeの赤い部分(赤い四角で囲んだ部分)をドラッグするとTop Methodに表示された内容をベースにRandom AccessFile 読込みに大半の時間が掛かることを確認できます。継続的にファイル読み込みがリトライされた可能性があります。
改善 トライ – 1
大半の時間がファイル読み込みに掛かるのでこれをより速くする方法はないのか?
JAVAでもファイルをメモリに直接マッピングして読み書きするメモリマップファイルを実装(Memory-Mapped File)できますが注意が必要です。そのため、別の改善方法を探してみます。
ここではピンク色の領域が最も幅が広いですが、その中でAbstractRecord.toObjectDB部分(上のスクリーンショットで紺色の四角で囲った部分)が気になります。

下位メソッドはRealtimeObjectRecord.read(紺色の四角で囲った部分)でInputStreamからバイトを決まった順番に読込みオブジェクトに変換する内容です。
この部分が総19.05% を占めるため、ここを早くすることで性能が改善できると思います。
protected IRecord read(InputStream in, boolean db) {
1. if (!db) {
2. this.time = TcpUtil.getlong(in);
3. }
4.
5. this.otype = TcpUtil.getbyte(in);
6. this.oid = TcpUtil.getint(in);
7. int count = TcpUtil.getshort(in);
8.
9. for (int t = 0; t < count; t++) {
10. short key = TcpUtil.getshort(in);
11. TYPE value = TypeUtil.next(in);
12. this.putValue(key, value);
13. }
14.
15. readTrustRangePart(count, in);
16. return this;
17. }
“特に改善する部分がないのでは… NIOのバイトバッファー(Byte Buffer)を利用すると、もっと良くなるんじゃないかな? もしかしたらメモリマップを利用すると中間変換の処理もなくすことができる…“
バイトをハンドリングすることがより便利になるByte Buffer を利用する方法で以下の様に変更します。
1. @Override
2. public IRecord read(ByteBuffer bb, boolean db) {
3. if (!db) {
4. this.time = bb.getLong();
5. }
6.
7. this.otype = bb.get();
8. this.oid = bb.getInt();
9. int count = bb.getShort();
10.
11. for (int t = 0; t < count; t++) {
12. short key = bb.getShort();
13. TYPE value = TypeUtilV2.next(bb);
14. this.putValue(key, value);
15. }
16.
17. return this;
18. }
変更したコードを適用して、再度照会結果を確認します。

スクリーンショットでは、先ず、Flame Scopeの色が前より薄い色になりました。これはある程度スレッドで実行されるタスクの時間が以前より短くなったことを意味します。下段のFlame GraphではAbstractRecord.toObjectDBが占める比率が9.03%(紺色の四角で囲った部分)であることが確認できます。 数値上では10%程度呼び出し頻度が減少しました!
次はX-View チャートで比較してみたいと思います。

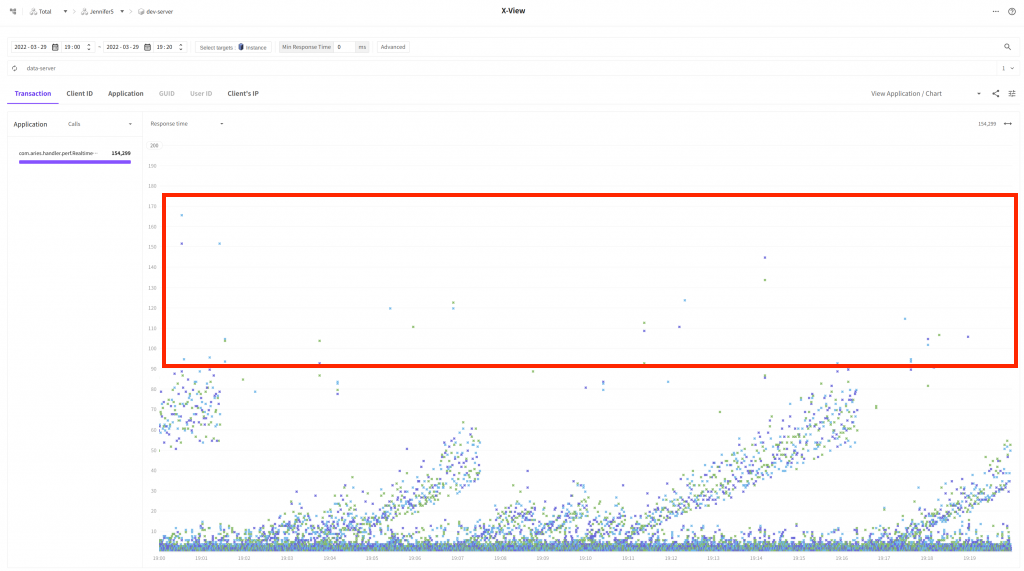
波の様な模様が確認できますが40ms ~ 110ms間の分布が多数無くなったことを確認できます。多くのリクエストの応答時間が改善されました。
改善トライ – 2
Yさんが波の様に上の位置に残っているトランザクションの応答時間も小さくするように改善したいと考えました。 改善トライ – 1で言及したMemory-Mapped Fileを利用して読込み部分を以下の様に変更しました。
1. private val map =
inner.raf().channel.map(FileChannel.MapMode.READ_ONLY, 0, inner.length())実現の簡単さを追求するため、読込み専用メモリマップを利用しました。コードを適用したYさんはスタックトレースレコーダー画面へ移動して照会ボタンをクリックしました。

今度はTop MethodにRandom Access関連の内容が確認できません。
X-Viewで照会した時も差がありますか?
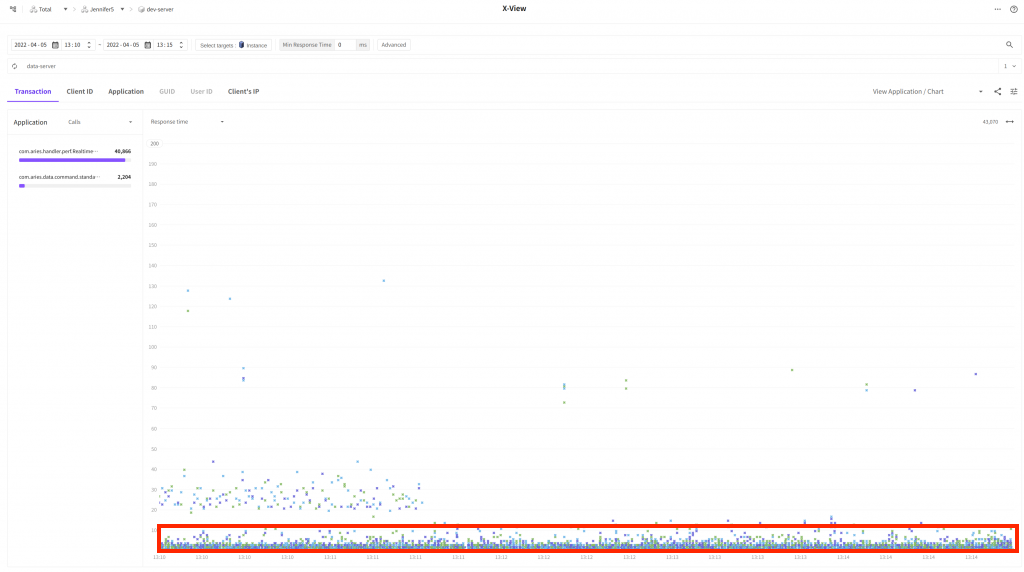
やっと一部トランザクションを除外した大半のトランザクションの応答時間が 10ms 未満に減少(赤い四角で囲った部分)しました。これでダッシュボードチャートの照会性能が改善されたことを確認できます。これで問題であった個別のリクエストが遅い…( 200msでも…)現象は大きく改善できました。
結論
過去のプロファイルのみ依存して性能改善を行う時に、難しかった様々な問題をシンプルに解決できました。プロファイルが多過ぎて本当に照会が難しかったことがありました。照会したプロファイルの個別応答時間が短すぎて分析が難しかったこともありました。また、ログにヒントを出力する別の分析ツールに依存することもありました。
しかし、Visual VMのソースコードを読んで多数のオープンソースを探して使えるスタックトレース基盤分析ツールを見つけることができました。この機能をより多くのユーザが有益に利用することを期待します。