
2023年12月06日
スタックトレースサンプリングを
利用した性能分析A
開発担当者Yさんの会社であるJ社はバージョンが古いインストール型製品のJiraを使用しています。IDCのどこかにインストールされていて、マシンも古いことは分っていますが、ライセンスポリシーがハードウェア単位に割り当てられているため、アップグレードも場所を移動してインストールすることも難しい状況です。
偶に、非常に遅くなる応答時間が何故遅いか分からずイライラしているYさん:
「どのようにパッケージを設定すると良いのかな? 先ず、モニタリングしてみよう!」
YさんはインストールしたAPMの機能であるX-Viewチャートで、Y軸の上の方に位置するトランザクションを確認できました。

X-ViewチャートのY軸の上段に表示されたトランザクション(スクリーンショットで紫色の〇)をドラッグします。

12秒以上のNot Profiled領域(青い四角で囲った部分)が存在します。そこで、トランザクションが終わりの方で12秒以上時間がかかる原因が気になります。
遅延する領域がSQL、HTTP呼び出しのような一般的なボトルネックポイントではないため、少し重い感じがします。Jiraはatlassian社の製品であるため、com.atlassianパッケージを対象にプロファイル設定をしました。

設定するとシステムCPU使用率が52%を超えました!
次にX-Viewチャートをドラッグしてみます。

多くのメソッドがプロファイリングされていますが、大半の経過時間が0ms、1msのメソッドを確認できます。
さらにX-Viewチャートを確認すると、サービスの応答時間がかなり遅くなっています。

では、プロファイリングをトライしたことは間違った方法でしょうか?
遅延の原因が、設定したパッケージ内のどのクラスのメソッドが原因か特定できるかもしれません。しかし、最近のアプリケーションは、ユーザが開発した特定メソッドの性能が非常に悪くても、応答時間に大きな影響を与えません。大半の開発環境では準備されたフレームワークを利用して開発するためです。
実際にcom.atlassianパッケージをプロファイリングすると目立ったプロファイル情報は確認できません。内部的にキャッシュを設置しても、これが性能問題に繋がる可能性は低いです。時間がかかるSQLまたはHTTP呼び出しがあれば、その呼び出し元をチューニングすることはありますが、関連情報がなければ原因の特定は難しいです。ローディングされたクラスに該当するパッケージ全てを設定すると(!!)探すことができますが。しかし、アプリケーションにさらに負荷がかかることと、データ量が非常に多くなる可能性があります。
このような状況で有効な分析方法には次のプロファイリングとサンプリングの二つがあります。
①プロファイリング
実行される各メソッドから性能情報を収集後、長時間に渡り実行したメソッドを探し出して改善します。

各メソッドの開始と終わりを追跡して応答時間を測定します。
図ではTransaction1、Transaction2の最も遅いメソッドは各Method2、Method4です。
②サンプリング
アプリケーションのメソッド呼び出し有無を周期的に収集して、呼び出し頻度が高いメソッドを探し出して改善します。

各スレッド(THREAD)の実行中のMethodのスナップショットを周期的に収集して応答時間を測定します。図ではMethod1が遅延の原因であると考えられます。
プロファイリングは一般的な性能分析方法であるため長年の実績があります。そのため、大半のモニタリング製品がプロファイリング中心の機能を基本的に提供しています。しかし、完璧に見えるプロファイリングでも次のような限界があります。
- モニタリングする対象のメソッドをユーザが特定する必要があり、運用担当者では難しい。
- 高いトラフィックの運用環境のアプリケーションに適用する時に、性能に影響する可能性がある。
しかし、実際に性能改善が必要とされるトラフィックは運用環境で発生しています。
どんな状況でもモニタリングできる方法があれば、プロファイリングの限界を補完できます。
その方法の一つが サンプリング です。
個別メソッドを直接追跡せず、メソッドが呼び出した各スレッドからスタックトレースを周期的に収集して、出現頻度を基にボトルネックを探す方法です。
例えば、スタックトレースを100ms周期で3回収集した時、aというメソッドが3回全てに出現した場合、aメソッドが300ms実行していたと考えられます。プロファイリングに比べて精度は少し落ちますが、性能に影響が少なくデータを収集することができます。
処理遅延の主な原因は次の通りです。
- CPUリソースを大量に使うメソッド
- I/Oを同期化して処理するメソッド
- サイズが大きいコレクションオブジェクトを繰り返すメソッド
- 不必要にスレッドを同期化処理するメソッド
スタックトレースを利用したサンプリングを利用すると、特別な設定もなく上記の項目に該当するメソッドを簡単に探すことができます。CPUを大量に消費し、I/O待ちで長い時間実行されるメソッドはスタックトレースに繰り返し確認できます。
勿論、サンプリングも新しい分析方法ではないため、使い易いツールが幾つかあります。Yさんの場合はVisualVMを主に使用しました。スレッド別スタックトレースを周期的に収集して呼び出し、出現頻度を見易く表示してボトルネックを簡単に探し出すことができます。

サンプリングは性能に与える影響が少ないため、トラフィックが多い運用環境でも利用できます。実際、Yさんは担当するAPM収集サーバの性能改善にも利用したことがあります。
トランザクションで収集された個別のスタックトレースの確認
JENNIFERもリアルタイムで必要なメソッドを簡単にプロファイリングすることができますが、具体的な確認ポイントを理解する必要があります。勿論、この問題を補完するために様々な方法があります。主にリアルタイムでスタックトレース情報を確認してプロファイリングの対象を探します。
- ソケットモニタリング機能を利用して、特定ポートのスタックトレースからプロファイルの対象を選別
- スレッドモニタリング機能を利用して、特定スレッドのスタックトレースからプロファイルの対象を選別
- ダイナミックスタックトレース機能を利用して、特定クラスまたはメソッドを呼び出したポイントまでのスタックトレースを確認し、プロファイルの対象を選別
上記の方法を利用しても探し出せなかった呼び出し区間は、X-View詳細確認ポップアップでNot Profiled領域として表示されます。

処理時間が長いNot Profiled領域があれば、モニタリングする担当者は当然その区間を確認します。トランザクション別スタックトレースを収集して収集時間を逆順で表示することにしました。

時間順に表示されたスタックを一つ一つ確認すると、トランザクション内でどんな動作があったかを確認できます。
上のスクリーンショットでは小さくて分かり難いですが、トランザクションの大半はThread.sleep()メソッドを継続的に呼び出しています。開発担当者がデモ環境のため、人為的に入れた動作と思われます。
jspのコンパイルされたクラスのメソッドをプロファイリングすると、jspServiceメソッドの実行時間が長いことを確認できます。根本的な原因は実際にコードを確認すると把握できます。
トランザクションで収集された複数のスタックトレースを視覚化
前の例ではトランザクションは比較的簡単な内容を実行するため、リストに表示されたスタックトレースだけでも大体原因を把握できます。しかし、実行時間が長いトランザクションで様々な種類のスタックトレースが100個程度収集された場合、多くの個別スタックトレースの一つ一つを全て確認する必要があり、非常に大変です。
JENNIFERではこのような状況でも簡単に分析できる次の二つの照会方法を提供します。
①要約確認
要約確認は各メソッド呼び出しの関係を分析し、要約してツリー構造で表現します。ツリーで表示された四角の棒グラフはスタックトレース内のメソッドを表していて、次の3つの情報を含んでいます。
※要約確認のスクリーンショットの事例はこれより下に記述があるので参照願います。

1. 応答時間
応答時間はスタックトレース内で一回でも出現すると、測定される数値です。
出現回数xスタックトレースの測定周期で計算して、応答時間が長いメソッドはシステム性能のボトルネックの開始点であると判断できます。
2. セルフタイム
セルフタイムはスタックトレースで最上段に位置するメソッドで測定される数値です。実行中のメソッドでこの数値が大きければシステムのボトルネックの可能性が高いです。主にI/Oを発生させるメソッドが多く、時にはCPUを多く消費するメソッドもあります。
3. 下位セルフタイム
下位セルフタイムはある一個のメソッドが呼び出した他のメソッドが持っているセルフタイムの合計です。この数値が大きいと、このメソッドが呼び出した、どのメソッドがスレッドで実行中であったかを予想できます。セルフタイムを持ったメソッドの開始点を探す目的で使います。下位セルフタイムが大きいノード(青色)を重点的に探して、その下位のセルフタイムが大きいノード(黄色)を探すと実行中だったメソッドを探すことができます。
②フレームチャート(Flame Chart)
ブランドングレッグ(Brandon Gregg)が提案したフレームチャートという視覚化方法です。一つの縦線は一つの種類のスタックトレースです。一つのノード上に複数のノードがある場合は、その時点で呼び出しが分岐したことを表しています。フレームチャートは次のような特徴があります。
- 色は同一のパッケージのメソッドを表す
- 四角の幅は収集回数
- チャートの最下段に表示されたメソッドはスタックトレースの開始ポイント
- チャートの最上段に表示されたメソッドは実行中のメソッド
以上の特徴に基づいて、チャートで最も広い部分を探すと照会期間で最も多く呼び出されたメソッドを探すことができます。探し出したメソッドはその時間帯で悪化している状態(CPU大量消費、応答時間の遅延)の主要原因の可能性が高いです。
※フレームチャートのスクリーンショットの事例はこれより下に記述があるので参照願います。
活用例
ここからはYさんの事例をJENNIFERで改善されたスタックトレース機能を利用して分析します。先ず、遅いトランザクションの詳細情報をX-Viewポップアップで確認します。

Not Profiledノード(赤い四角で囲った部分)が大半の処理時間を占めています。
Not ProfiledノードにSTACK-TRACE(青い四角で囲った部分)という、下位のノードがあることを確認できます。これは全てのプロファイルと時間情報を基にスタックトレースの収集位置を表示しました。上のスクリーンショットではNot Profiled区間で95個のスタックトレースが収集されたことを表しています。
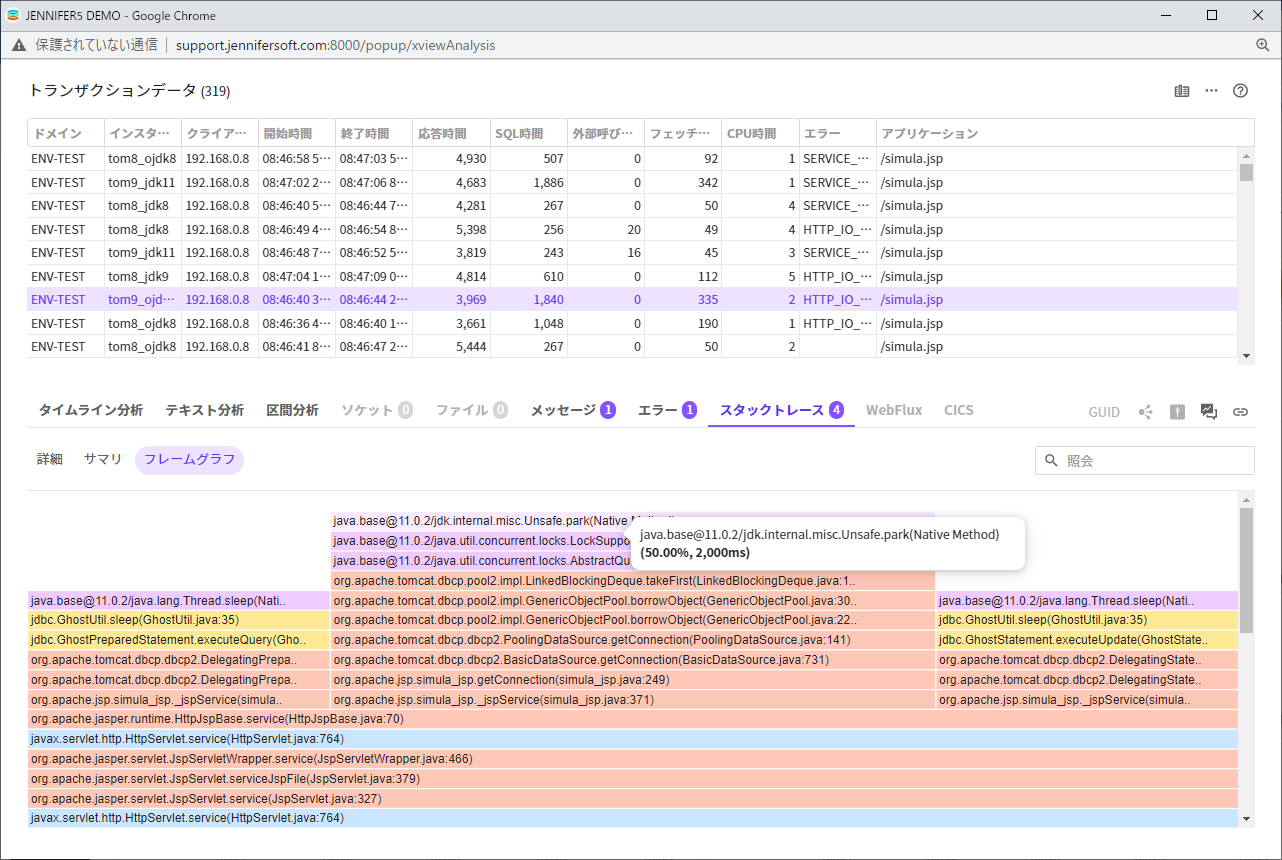
次に、STACK-TRACEノードをクリックすると、スタックトレースタブへ移動して、マッチングされるスタックグループが自動的に選択されます。


選択された時間に95個のスタックトレースが収集されました。
左側に表示される時間はスタックが収集された時間です。色はスタックトレースの種類です。色が連続的に繋がることは同じメソッドが連続して実行中であることを示しています。以前のタイムラインのタブのように該当時間区間に95個のスタックトレースが存在することを確認できます。なお、時間の前にある縦の棒の色はスタックトレースの種類を表しています。
同じ色が続く区間がある場合は、連続的に多く収集されたことで、同じメソッドが長い時間実行されたと予測できます。つまり、遅いメソッドです。このトランザクションの場合、String.intern()メソッドが何回も呼び出されています。
スクロールして同じ色が繋がる部分を探すことができますが、次の要約確認とFlameグラフを利用すると、より簡単に実行時間が長いメソッドを探すことができます。
①要約確認
要約確認をクリックすると次のような内容を確認できます。

収集された95個のスタックトレースに表示されたメソッドの呼び出し関係を統合して一つのツリーで表現します。ここで黄色の棒グラフが最も広い領域を占めたノードを探すと、それが最も多く実行中であって、最も遅いメソッドです。
String.intern()メソッドが37.89%を占めていることを確認できます(時間は3.6秒程度)。薄い青色の棒グラフで表示されたメソッドはこのような遅いメソッドが含まれているメソッドです。分析する観点で実行中のメソッドではない最も多く呼び出されたメソッドから探す場合に、このノードを重点的に探します。
②フレームチャート(Flame Chart)

四角い領域の最上段に位置して最も広い部分(赤い四角で囲った部分)にあるのが最も遅いメソッドです。java.lang.String.intern()メソッドが最も多く実行中であったことを確認できます。
一行下のメソッドはjava.lang.String.intern()メソッドを呼び出したメソッドのcom.atlassian.jira.web.bean.BackingI18n.flattenResourceBundlesToMap(BackingI18n.java:658)メソッドです。
このように3つの方法で最も長く実行中だったメソッドはString.internで、これを呼び出したメソッドはBackingI18n.flattenResourceBundlesToMapであることを確認できます。
このメソッドが遅い理由が気になります。BackingI18nクラスを確認するとパッケージ名がatlassianで、Jira社製品のコードです。ソースコードの確認や修正はできません。
次にString.internメソッドを分析します。
基本的にJDKがサポートするネイティブメソッドでJVMが管理する文字列プールにパラメータで伝達された文字列を、文字列プールに文字列が無いと入れて返還、あると何もせず返還します。つまり、同じ文字列を重複して生成しないようにしてメモリ使用率を下げることができます。しかし、それが3秒以上かかることが少し気になります。
そこで、次のように該当メソッドをキーワードで検索してみます。

検索結果を確認するとJDKバージョン別に実装が異なるため、動作するString.internメソッドの情報を確認できます。
http://java-performance.info/string-intern-in-java-6-7-8/
上記のリンクの内容は次の通りです。
Yさんの会社で使用中のJiraは非常に古いバージョンです。使用中のJDKバージョンを確認します。

つまり、JDKバージョンは1.7.0_25です。
そこで、文字列プールのデフォルトサイズが1009で、これより多い文字列が持続的に累積され、適切なハッシュ分散が行われないと仮定します。すると、マップ内のデータが適切なハッシュアルゴリズムで分散されない場合は、データの件数が多くなると照会時間が遅くなります。
これが性能低下の原因であれば文字列プールのサイズを大きくして、ある程度の性能改善効果を期待できます。次のようにJira実行スクリプトに文字列プールサイズを設定しました。サイズはJDK8のデフォルトサイズと同じ数値を適用しました。

Jiraを再開後、状態を確認します。
1ヶ月後
オプション適用後Jiraの応答時間はかなり改善されました。
設定変更前の性能情報をJENNIFERで収集してどの程度改善されたかを確認しました。
データで確認するためにアプリケーション状況、性能ブラウザ機能を利用して改善前後の状態を比較しました。
①アプリケーション状況
下記の内容は呼び出し件数で降順にソートして照会しました。


比較すると平均、最大応答時間の両方が改善されたことを確認できます。
②性能ブラウザ
性能に影響を与えるいくつかの要素を、性能ブラウザ機能を利用して比較します。

緑色が既存の状態で、紫色ラインが適用一ヶ月後の状態です。ピーク時点の時間が全般的に改善されたことを確認できます。

水色ラインが改善前、紫色ラインが改善後です。改善後のトランザクション当たりCPU時間が大幅に減少したことを確認できます。体感的に改善された部分が数値で証明されたことになります。
③X-View
最後にX-Viewチャートで改善前後のデータを比較します。


改善後は全般的にトランザクションが下の方に集まっていることを確認できます。全体的に応答時間が改善されたことを示しています。
結論
自分が経験したサンプリング基盤分析機能の効果を読者に伝えるために適切な例を探すのが難しかったですが、偶に周期的に性能が悪くなる現象がみられるインストール型Jira(イシュー管理システム)で運用システムの性能改善の事例を紹介できる機会があってうれしく思います。
ここで紹介した事例では、一般的にはメソッドプロファイリング法でこのような結果を出すのは非常に難しいと思います。java.langパッケージをプロファイリングすることは正しいアプローチではありません。問題で確認できたString.internメソッドはネイティブメソッドであるため有効でした。
今回紹介したJENNIFERの機能が少しでも多く性能改善ポイントを探し出して、解決にお役に立てれば幸いです。
JENNIFERは個別トランザクションのスタックトレースのみならず、システム全体のスタックトレースを基盤とした分析機能を提供します。それは、トランザクションの観点で分析できない性能問題を解決する時に役立つ機能です。