
2023年11月27日
JENNIFERによる
効率的な性能監視の方法
1. アプリケーションの可視化で性能問題を解決します
ダッシュボード➡システムアドミン
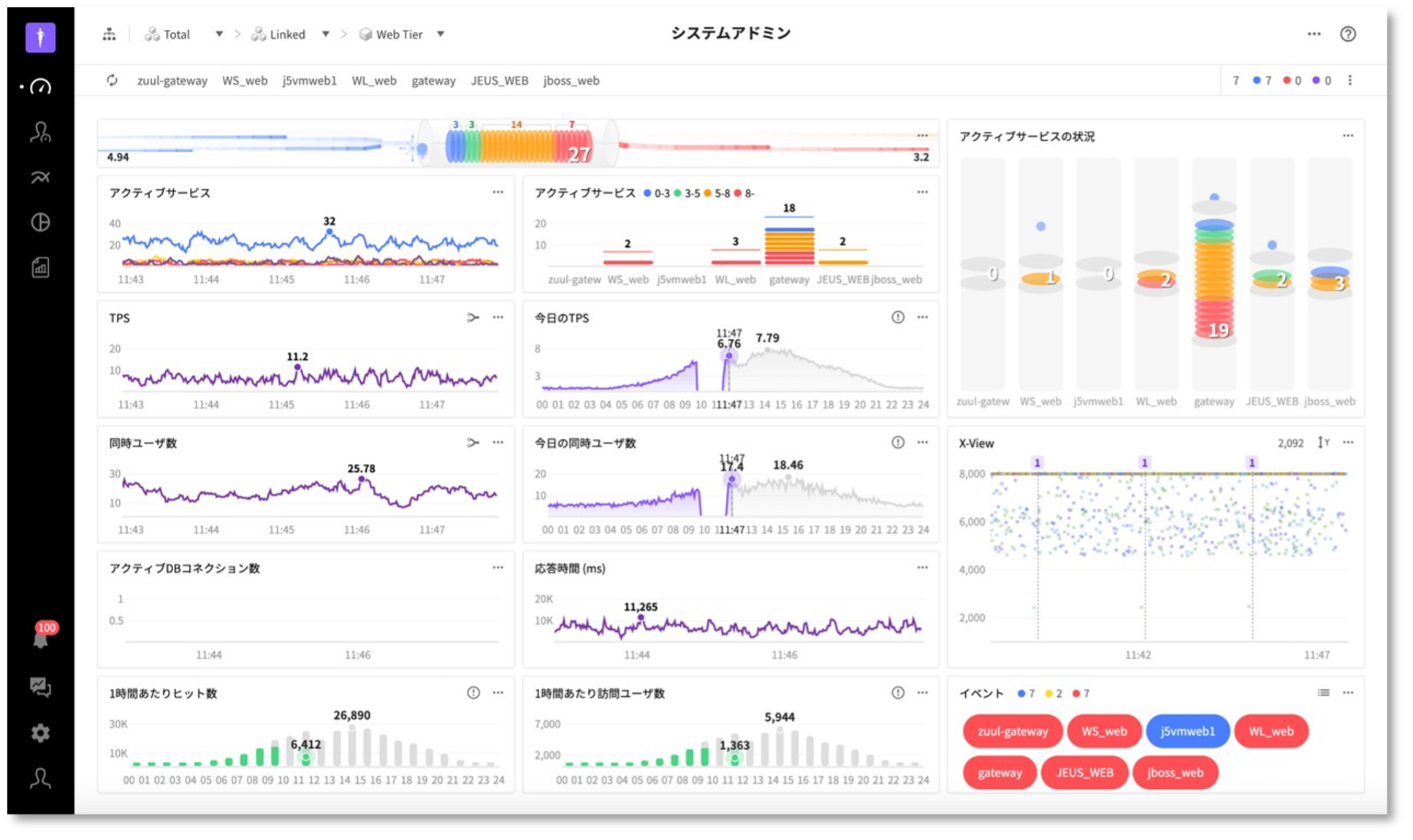
ダッシュボード➡システムアドミン(リソース)

2. アプリケーションの性能監視と性能情報の比較によって、性能問題の予兆を検出できます
ここでは、次の2つの観点から分析を行います。
- 1)時系列でトランザクション数、ユーザ数、エラー等の変化の観察
- 2)システム特性の関連性の観察
1)時系列でトランザクション数、ユーザ数、エラー等の変化の観察
時系列の変化を次の3 つの傾向に分類して考察します。
- a. 全体的に直線的に変化する傾向
- 例:前年比で増えている変化
- b. 周期性を持って変化する傾向
- 例:季節や曜日によって業務量が定期的に変わる変化
- c. 突発的な変化を伴う傾向
- 例:新商品の発売開始やキャンペーン期間等で発生

a.全体的に直線的に変化する傾向
分析➡ソースコード(リソース)変更履歴

ダッシュボード➡メモリ

b.周期性を持って変化する傾向
統計➡月別システム性能情報

c.突発的な変化を伴う傾向
統計➡期間システム性能情報

ダッシュボード➡システムアドミン(リソース)


この様に傾向を把握できれば、直線的や周期的な変化から当初の予測と実際の差はどの程度か、現在の傾向が続くと仮定すると、何時まで安定的にシステムを運用できるかといった診断を行うことができます。
また、突発的な変化についても、過去の発生状況とその理由を分析することで、次回突発的な変化が予測される影響の程度を見極めることができます。
2)システム特性の関連性の観察
異なる分析の観点としては、トランザクション、ユーザ、CPU、メモリ、応答時間等の個々の性能データの関連性を比較することで、問題の予兆を検出できます。
応答時間が遅くなった状態では、次の3つのことを確認します。
- ① トランザクションはどのように変化しているか?
- ② CPU、メモリ等のリソースはどのように変化しているか?
- ③ 同時ユーザ数はどのように変化しているか?
業務量の増加した状態では、次の2 つのことを確認します。
- ① 応答時間あるいは処理時間はどのように変化しているか?
- ② CPU 使用率などリソースはどのように変化しているか?
分析➡性能ブラウザ

分析➡アプリケーション状況






このような分析を過去の分析結果と比較することで、システム内部の変化を把握できます。
3.早めの対策
分析結果に対応したチューニングを行います。チューニングの目的は、システムを最適化して求められる業務性能を満たすことですが、対応方法は様々です。
過去の分析との比較は、原因の絞り込みや対策の立案に役立ちます。立案と並行して、新たな監視項目の追加や閾値の見直しを検討することで、性能管理の仕組みをブラッシュアップできます。
例えば、業務量が急激に増加していれば、システム増強の時期を見直す必要があるかもしれません。イベントに起因する業務量の増加が問題であれば、新商品の発売時期をずらす等、イベントの発生時期をコントロールする対策も有効でしょう。
システム特性の変化が発生しているのであれば、ミドルウェアのパラメータ変更、アプリケーションの修正の有効性を検証することも考えられます。
4.問題がなくても繰り返すことが大事
システムの状態を継続的に計測し、把握するという活動は、即座に価値を生み出すものではありません。最悪の事態に備えるために一定の対価を払うという意味で、保険と似ています。
問題が顕在化してから対処し、再発防止策を講じるといった方法だけでは限界があります。システムライフサイクルの中で問題が発生する可能性やその影響を考慮して、適切な性能管理を検討することが肝要です。
これまで述べた性能監視、分析、チューニングおよび実装の一連の作業が、キャパシティプランニングの基本サイクルとなります。キャパシティプランニングは、品質管理における PDCA サイクルであり、繰り返すことが大切です。