
2025年01月31日
第16回
アラートシステムRobustaと
Grafanaの構築
1. システム運用で重要なモニタリングとアラート
筆者はシステム運用で最も重要なことは、モニタリングとアラートだと考えています。システムの状態をアラートにより、自動で迅速に把握することで運用の効率性を向上できます。複雑なプロセスがなくて重要な情報を見逃さず、素早く確認できることがアラートシステムの意義です。運用担当者が一つ一つシステムの状態を確認することは現実的に不可能です。
実際に効果的なアラートシステムを実装することは簡単に見える部分もありますが、非常に難しい課題です。障害発生後に、アラートの設定が不十分であることに気づくことはよくある話です。このような状況を事前に防止し、迅速に対応できる能力を持つ者が優れたシステム管理者、 DevOps専門家です。その実装は一回で終わらないため、継続的な最適化が必要です。
クバネティスでも既存のITサービスと同様に、きちんと動作するアラートシステムを構築することは非常に重要なことです。
2. アラートシステムの前提条件
クバネティス環境のアラートシステムは、既存のシステムと同様に次の条件を満たすことが重要です。
- 漏れのない多様なアラート – 複雑なクバネティスの状態を確認できるアラートを提供できるか?
アラートシステムは多様な運用状況と障害条件を包括する必要があります。システムの全ての重要な側面をモニタリングできる完全なアラートが事前に設定されている必要があります。コンサルティング業界で多く使用する MECE(Mutually Exclusive Collectively Exhaustive)つまり、 漏れがなく、重複しないアラートが必要です。
- メッセージの可読性と明確性 – メッセージだけを見て、システム管理者またはサービス担当者はどのような問題かを素早く把握できるか?
アラートメッセージは明確、単純で理解し易くなければなりません。管理者がメッセージを素早く読めて、問題の本質を直ぐに把握できる必要があります。
- 重複メッセージとアラートの頻度 – 類似するメッセージが頻繁に発生してアラート疲労の発生や、重要ではないメッセージで、重要なメッセージの見逃しが発生していないか?
よくある問題です。アラート疲労も重要です。経験による適切な頻度の設定が必要です。アラート設定では不要なアラートを削除することも重要ですが、これを軽く考えていることがよくあります。
- 即時性 – 問題が発生した時に直ぐにアラートが発生しているか?
アラートは問題が発生した時に、またはできる限り早く知らせるべきで、管理者が迅速に対応できるようにします。次に発生するかもしれないより大きい問題の発生前に、最大限早いアラートの発行が必要です。
- 予防的アラート – できれば問題の発生前に異常を検知し、事前のアラート発行、またはサービスに影響を及ぼす問題の発生前に小さい問題を検知できるか?
アラートシステムは潜在的な問題や障害を事前に検知し、アラートを発行して、問題の発生前に予防措置ができるようにする必要があります。
- デフォルトの運用機能の提供
アラートシステムは Sleep(一時停止)モードと同様な運用的にアラートの停止機能を提供するべきで、アラートの稼働と必要であれば一時停止ができるようにする必要があります。システムの定期作業の時には、アラートを一時停止する場合がその一例です。
- アラート設定の容易性
ユーザが簡単に追加アラートを設定し、調整できる必要があります。システムの変化と新しい要件に素早く対応する時には必須です。
- 統合と拡張性
アラートシステムは既存のモニタリングシステムと円滑に統合され、必要であれば簡単に拡張できる必要があります。多様な環境とツールとの相性も重要です。
では、このような条件をどのように満足すべきかを実習で確認します。
3. prometheusアラートルール
prometheusコミュニティ Helmチャートでインストールすると、デフォルトでクバネティス運用に必須で多様なアラートルールが組込まれます。このルールは下記の様に prometheusRulesカスタマイズリソースで確認できます。 promehteusrulesもクバネティスリソースの k getコマンドで確認できます。
1. (jerry-test:monitoring)~$ k get prometheusrules.monitoring.coreos.com -A
2. NAMESPACE NAME AGE
3. monitoring prometheus-kube-prometheus-alertmanager.rules 13h
4. monitoring prometheus-kube-prometheus-config-reloaders 13h
5. monitoring prometheus-kube-prometheus-general.rules 13h
6. monitoring prometheus-kube-prometheus-k8s.rules 13h
7. monitoring prometheus-kube-prometheus-kube-prometheus-general.rules 13h
8. monitoring prometheus-kube-prometheus-kube-prometheus-node-recording.rules 13h
9. monitoring prometheus-kube-prometheus-kube-state-metrics 13h
10. monitoring prometheus-kube-prometheus-kubelet.rules 13h
11. monitoring prometheus-kube-prometheus-kubernetes-apps 13h
12. monitoring prometheus-kube-prometheus-kubernetes-resources 13h
13. monitoring prometheus-kube-prometheus-kubernetes-storage 13h
14. monitoring prometheus-kube-prometheus-kubernetes-system 13h
15. monitoring prometheus-kube-prometheus-kubernetes-system-apiserver 13h
16. monitoring prometheus-kube-prometheus-kubernetes-system-kube-proxy 13h
17. monitoring prometheus-kube-prometheus-kubernetes-system-kubelet 13h
18. monitoring prometheus-kube-prometheus-node-exporter 13h
19. monitoring prometheus-kube-prometheus-node-exporter.rules 13h
20. monitoring prometheus-kube-prometheus-node-network 13h
21. monitoring prometheus-kube-prometheus-node.rules 13h
22. monitoring prometheus-kube-prometheus-prometheus 13h
23. monitoring prometheus-kube-prometheus-prometheus-operator 13h
24. redis redis 10d
このように多くのルールを確認できます。特別な設定なしで既に多様なルールが組込まれています。また、ルールを describeコマンドで詳細に確認すると、シングルアラートではないマルチアラートがルールに設定されていることが確認できます。
1. (jerry-test:monitoring)~$ k describe prometheusrules.monitoring.coreos.com prometheus-kube-prometheus-kubernetes-apps
2. Name: prometheus-kube-prometheus-kubernetes-apps
3. (中略)
4. Rules:
5. Alert: KubePodCrashLooping
6. Annotations:
7. Description: Pod {{ $labels.namespace }}/{{ $labels.pod }} ({{ $labels.container }}) is in waiting state (reason: "CrashLoopBackOff").
8. runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepodcrashlooping
9. Summary: Pod is crash looping.
10. Expr: max_over_time(kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff", job="kube-state-metrics", namespace=~".*"}[5m]) >= 1
11. For: 15m
12. Labels:
13. Severity: warning更に設定を確認すると、上記のルールは Podの状態がCrashLoopBackOff(reason)で15分(For)持続されると深刻度(Severity)がwarningのアラートを発生する設定です。このように似ている設定が他のルールでも含まれていて、ルール毎に詳細を確認できます。
コマンドのみならず全体のアラートルールのリストは Prometheus GUIでも確認できます。
1. (jerry-test:monitoring)~$ k port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090
2. Forwarding from 127.0.0.1:9090 -> 9090
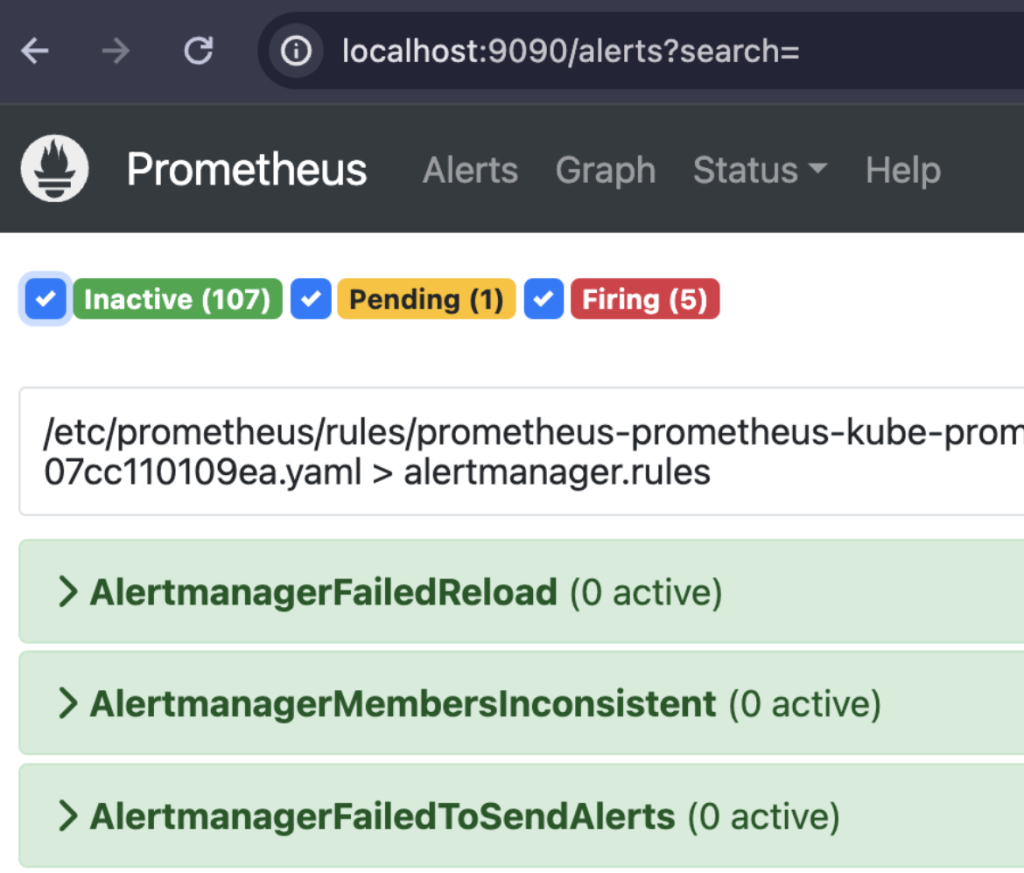
3. Forwarding from [::1]:9090 -> 9090画面上段の Alertsメニューを選択すると、下記の様に 113個のルールを確認できます。筆者の経験上、事前に提供するこのアラートルールだけでアプリケーションアラートを除いて、デフォルトクバネティスクラスター運用で必要なアラートのほぼ全てが含まれています。また、インハウスで作成したアプリケーションとKafka、MySQL等のパブリックアプリケーションに関するアラート設定は、Grafanaダッシュボードに別途でアラートルールを作成できます。
4. Slackアラートチャネルの準備
次にアラートを受信するチャネルを設定します。アラートを受信するチャネルは Slackを利用します。 Eメールも可能ですが、ヒストリー照会、詳細チャネルの分離と複数のメンバーが一緒に確認できる開放性から考えてSlackを選択しました。
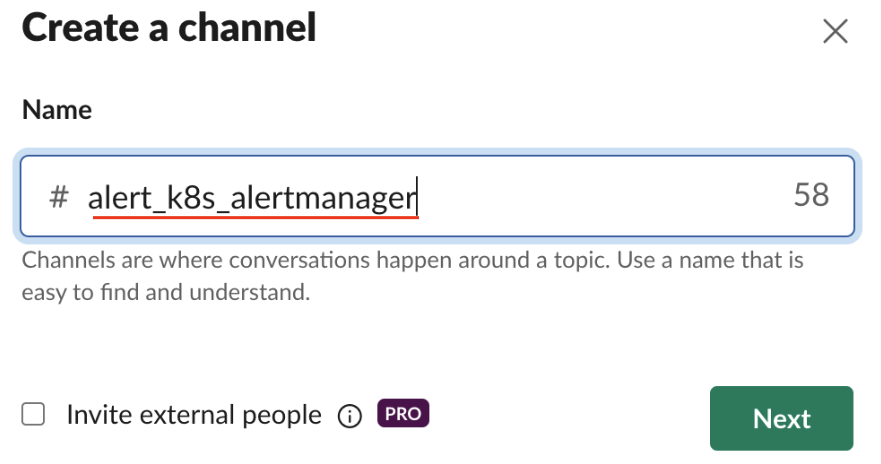
Slackでクバネティスアラートを受信する新しいチャネルを生成します。名前は任意に下記の様に決められます。しかし、これから類似するアラートチャネルを複数作成する予定のため、事前に命名規則(Naming Convention)を指定することを推奨します。筆者はalert_k8s_alertmanagerを指定しました。 alertmanagerは prometheusが提供するアラート関連リソース名です。
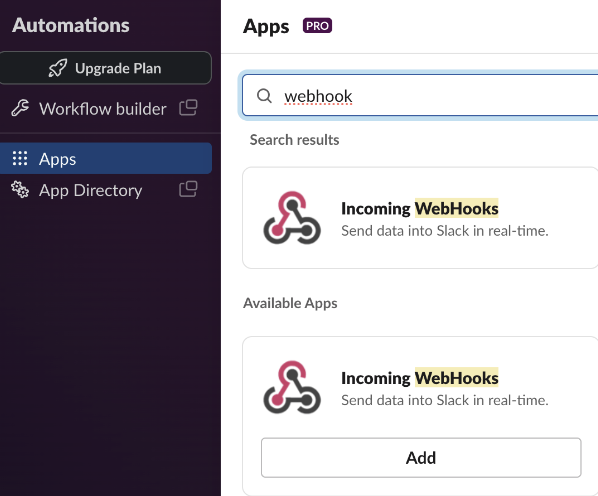
WebHooksでクバネティスアラートを転送する予定であるため、Slackの Appsメニューを選択して‘webhook’と入力します。
Webhookは Webアプリケーション間にデータを転送するための方法の一つです。これはある種のHTTPコールバック(callback)で、2つ以上の Webアプリケーションの間に特定イベントが発生する時に他のアプリケーションにアラートを送る時によく使用されます。
WebHooksを選択し、続く画面で先ほど生成したチャネルを選択します。
チャネル名を入力すると、下記のような Webhook URLを確認できます。外部サービスでこの URLを利用して Slackにメッセージを発行します。なお、この URLを公開すると、他のユーザがこのリソースを使用できるのでGithubなどに公開しないように注意して下さい。

次の設定でこの URLを使用する予定のため、保存します。
5. Prometheus – コミュニティ Helmチャートを利用したAlertManagerのインストール
Alertmanagerは prometheusで提供するアプリケーションが送信したアラートを処理するツールです。これは重複の削除、グループ化、正当な受信者を統合(例: Eメール、PagerDuty、OpsGenie)し、アラートをルーティングする役割をします。また、アラートの沈黙(silencing)と抑制(inhibition)機能も提供します。アラートの抑制とは類似するアラートが重複して発生させないことです。
以下の prometheusアーキテクチャー図で AlertManagerは右側の上段に位置するアラート機能を担当します。
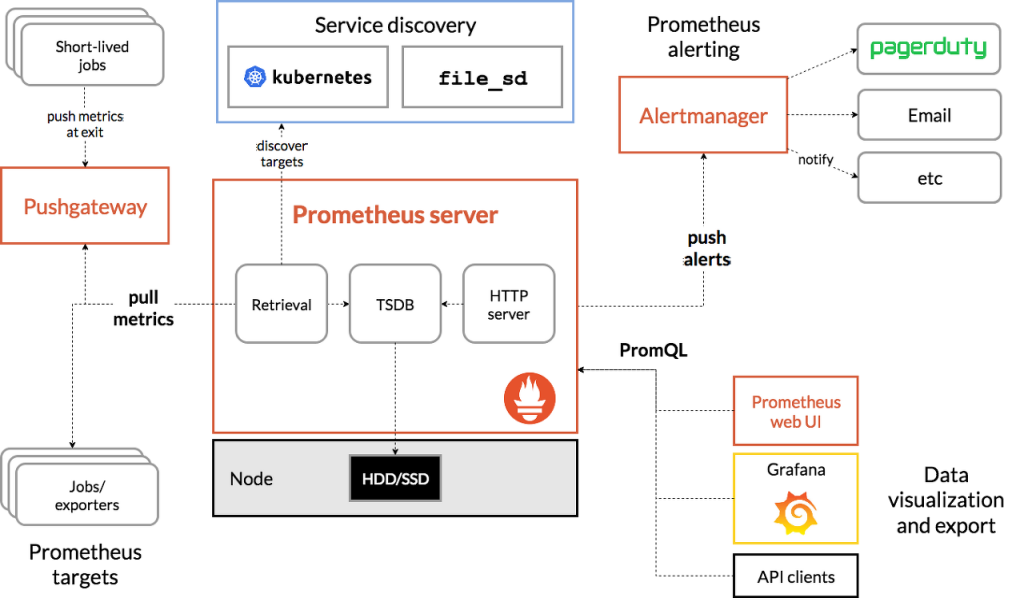
AlertManagerはGrafanaと同様に便利で、 prometheus-コミュニティHelm チャートに関連する設定を統合して提供します。
1. ## Configuration for alertmanager
2. alertmanager:
3. enabled: true
4. config:
5. route:
6. group_by: ['namespace']
7. group_wait: 30s
8. group_interval: 2m
9. repeat_interval: 6h
10. receiver: 'slack-notifications'
11. routes:
12. - receiver: 'slack-notifications'
13. matchers:
14. - alertname =~ "InfoInhibitor|Watchdog"
15. receivers:
16. - name: 'slack-notifications'
17. slack_configs:
18. - api_url: "{{ SLACK_API }}" # ここにSlack Webhook URLを入れます。
19. channel: '#alert_k8s_alertmanager' # メッセージを送るSlack チャネル
20. send_resolved: true
21. title: '{{ template "slack.default.title" . }}'
22. text: "summary: {{ .CommonAnnotations.summary }}\ndescription: {{ .CommonAnnotations.description }}". alertmanager.config.route.receiver: slack-notifications
アラート転送チャネルにslackを使用します。もし、emailを使用する場合は email-config設定を使用します。 Slackはよく使用される設定で、Valuesファイルで標準の設定を提供します。
. receivers: slack_config.api_url
前に生成したWebHook URL情報を入力します。 なお、Github等で外部に公開しないように注意します。
. receivers: slack_config.channel
チャネル名を指定します。筆者は ‘alert_k8s_alertmanager’を入力しました。
追加の send_resolvedはアラートが解除された旨のメッセージを送る設定で、titleとtextの設定はアラートメッセージのタイトルと内容を指定します。
上記の設定を追加して prometheus Helmをアップグレード(helm upgrade)します。 diffコマンドで先ず確認し、アップグレード作業を行います。
1. (jerry-test:monitoring)kube-prometheus-stack-48.3.1$ helm diff upgrade prometheus -f ci/my-values.yaml .
2. (jerry-test:monitoring)kube-prometheus-stack-48.3.1$ helm upgrade prometheus -f ci/my-values.yaml .AlertManagerは別途の UIを提供します。 UIで設定内容を確認します。先ず、port-forwardで接続します。
1. (jerry-test:monitoring)~$ k port-forward svc/prometheus-kube-prometheus-alertmanager 9093:9093
2. Forwarding from 127.0.0.1:9093 -> 9093
3. Forwarding from [::1]:9093 -> 9093画面上段のメニュー Statusを選択します。

Alertmanager関連の設定と状態(Status)の情報を確認できます。また、下記ではHelmチャートで修正したslack_configs関連の設定が正常に追加されたことを確認できます。

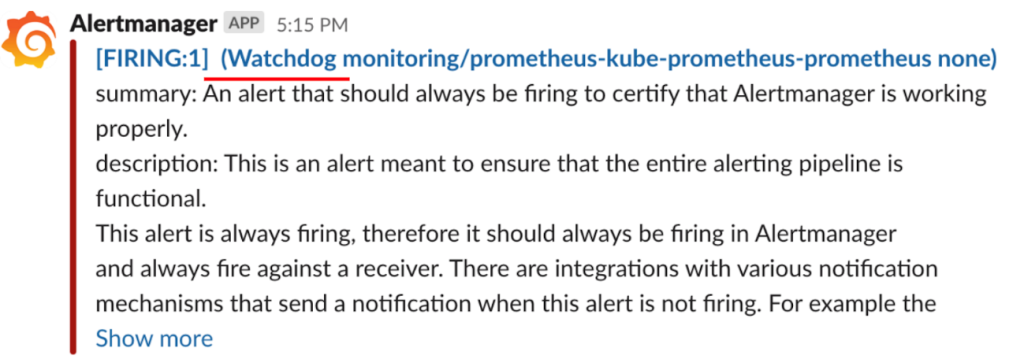
正常に設定されると、Slackでアラートを確認できます。下記のWatchdogメッセージは AlertManagerにSlackが正常に連動された旨のメッセージです。 AlertManagerに問題が発生してアラートを受信できない場合、Watchdogメッセージで正常か異常かを判断できます。
しかし、筆者はAlertManagerでは不十分であると感じています。障害が発生した場合、 AlertManagerのメッセージが不明確で、一回で障害の原因を究明することは難しいです。UIもあまり直観的ではありません。
実習で任意に CrashLoopBackOff Podを実行します。
1. (jerry-test:default)~$ kubectl apply -f https://raw.githubusercontent.com/robusta-dev/kubernetes-demos/main/crashpod/broken.yaml5分間の状態の確認と15分間の障害継続時間を過ぎた20分が経過すると、下記のアラートメッセージを確認できます。
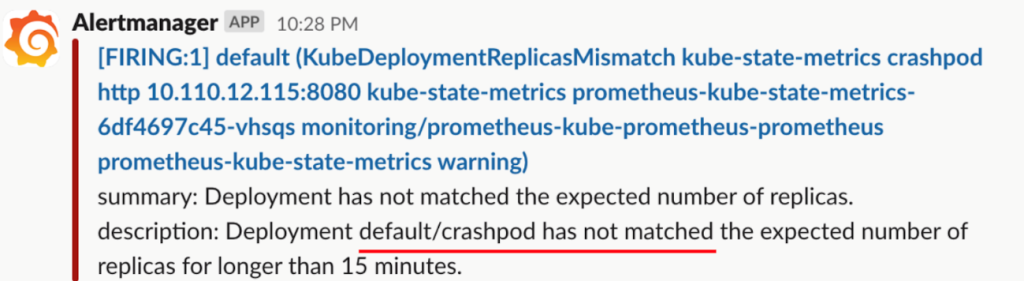
アラート時間の間隔は変更できます。しかし、各設定を一つずつ変更することは面倒で、見逃す可能性がある作業です。また、アラートメッセージが直観的ではないため、内容の把握が難しいです。
そこで、筆者は追加アラートシステムにRobustaを使用します。次のパートで確認します。
参考までに、CrashLoopBackOffの問題を解決すると、下記の解決完了(RESOLVED)のメッセージが転送されます。

6. Robusta – 直観的なアラートシステム
Robustaはクバネティス(Kubernetes)クラスター用の自動化されたアラート発行と問題解決のためのプラットフォームです。前に確認したアラートマネージャーに比べ、直観的なアラートメッセージを発行することがメリットです。上記のCrashLoopBackOffアラートの事例がより直観的に把握できます。
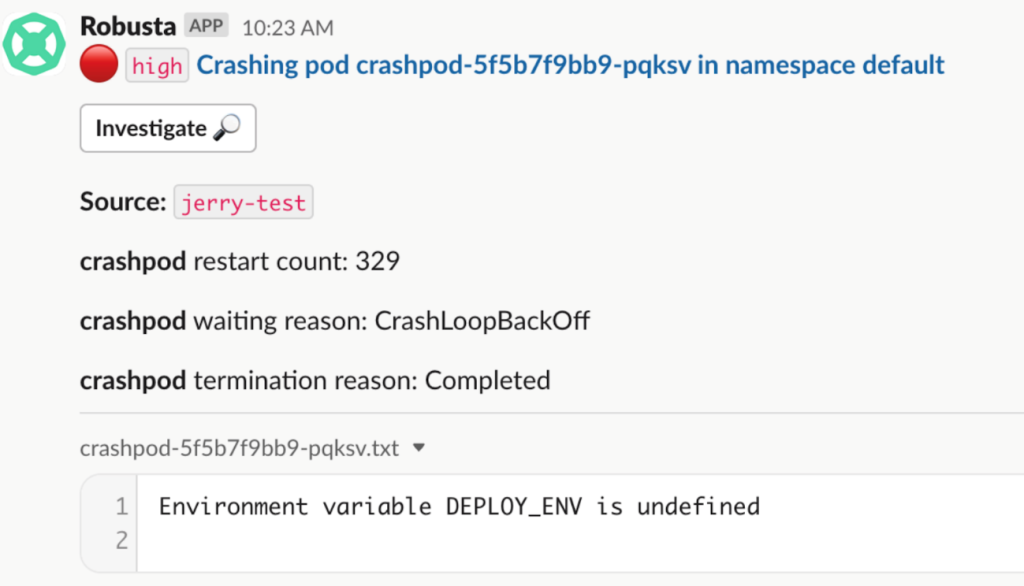
プラットフォームはクバネティスシステムのイベントとメトリクスをリアルタイムでモニタリングし、潜在的問題が発生した時に自動的にアラートを発行します。ユーザは Robustaにより、クバネティスクラスターの運用効率を向上でき、アラート管理と対応の過程を簡略化できます。
公式ホームページガイドにより Robustaをインストールします。 Helmで直ぐにインストールはできません。設定関連のセキュリティー情報が必要で、robusta CLIで先ず、設定ファイルを生成します。
1. [(jerry-test:default) ~]$ pip3 install -U robusta-cli --no-cache Robustaのインストール時に、 prometheusを同時にインストールできますが、一般的に prometheusがインストールされた環境に、追加でインストールする場合が多いです。 prometheusをインストールしないオプション(–no-enable-prometheus-stack)を選択します。追加でSSL関連エラーが発生しないように、下記の認証書関連のコマンドを事前に実行します。
1. (jerry-test:redis)robusta$ security find-certificate -a -p > ~/all_mac_certs.pem;
2. (jerry-test:redis)robusta$ export SSL_CERT_FILE=~/all_mac_certs.pem;
3. (jerry-test:redis)robusta$ export REQUESTS_CA_BUNDLE=~/all_mac_certs.pem
4.
5. (baas-dev-01:monitoring)~$ robusta gen-config --no-enable-prometheus-stack --debug
6. Robusta reports its findings to external destinations (we call them "sinks").
7. We'll define some of them now.
8.
9. Configure Slack integration? This is HIGHLY recommended. [Y/n]: n
10. Configure MsTeams integration? [y/N]:
11. Configure Robusta UI sink? This is HIGHLY recommended. [Y/n]:
12. Enter your Google/Gmail/Azure/Outlook address. This will be used to login: erdia22@gmail.com
13. Choose your account name (e.g your organization name): My-Robusta
14. Successfully registered.
15.
16. Please read and approve our End User License Agreement: https://api.robusta.dev/eula.html
17. Do you accept our End User License Agreement? [y/N]: y
18. Last question! Would you like to help us improve Robusta by sending exception reports? [y/N]: y
19. Saved configuration to ./generated_values.yaml - save this file for future use!
20. Finish installing with Helm (see the Robusta docs). Then login to Robusta UI at https://platform.robusta.devデフォルト設定でインストールし、Slack関連の設定はインストール後に追加できるため、デフォルト設定オプションを変更するので nを選択しました。後のSlack関連の設定で説明します。
コマンドを実行したディレクトリを確認すると、./generated_values.yamlファイルを確認できます。このファイルは Robustaのインストールに必要なアカウント情報とトークン情報等のセキュリティーに敏感な情報が含まれているので、セキュリティー対策上、外部の Github等に公開しません。必要であればSOPS等の暗号化モジュールを使用して共有します。
次はインストールのために Robusta Helmファイルをダウンロードします。
1. (jerry-test:redis)robusta$ helm repo add robusta https://robusta-charts.storage.googleapis.com && helm repo update
2. "robusta" has been added to your repositories
3.
4.
5. (baas-dev-01:monitoring)robusta$ helm pull robusta/robusta
6. (baas-dev-01:monitoring)robusta$ tar xvfz robusta-0.10.25.tgz
7. (baas-dev-01:monitoring)robusta$ rm -rf robusta-0.10.25.tgz
8. (baas-dev-01:monitoring)robusta$ mv robusta/ robusta-0.10.25前で保存した設定ファイル(~/generated_values.yaml)でインストールします。 clusterName(クラスター名)は任意の名前に変更します。
1. (baas-dev-01:monitoring)robusta-0.10.25$ helm install robusta -f ~/generated_values.yaml --set clusterName=baas-dev-01 .
2. NAME: robusta
3. LAST DEPLOYED: Sun Dec 10 14:09:41 2023
4. NAMESPACE: monitoring
5. STATUS: deployed
6. REVISION: 1
7. TEST SUITE: None
8. NOTES:
9. Thank you for installing Robusta 0.10.25
10.
11. As an open source project, we collect general usage statistics.
12. This data is extremely limited and contains only general metadata to help us understand usage patterns.
13. If you are willing to share additional data, please do so! It really help us improve Robusta.
14.
15. You can set sendAdditionalTelemetry: true as a Helm value to send exception reports and additional data.
16. This is disabled by default.
17.
18. To opt-out of telemetry entirely, set a ENABLE_TELEMETRY=false environment variable on the robusta-runner deployment.
19.
20. Visit the web UI at: https://platform.robusta.dev/初めてインストールすると、システム同期の関連作業が必要で、5分程度かかります。下記のログメッセージで同期が完了したかを確認します。
1. k stern robusta
2. (省略)
3. robusta-forwarder-54664c994c-xtvwc kubewatch time="2023-12-04T09:15:23Z" level=info msg="Message successfully sent to http://robusta-runner:80/api/handle at 2023-12-04 09:15:23.220129534 +0000 UTC m=+80.076064545 "
4. robusta-forwarder-54664c994c-xtvwc kubewatch time="2023-12-04T09:15:23Z" level=info msg="Message successfully sent to http://robusta-runner:80/api/handle at 2023-12-04 09:15:23.221390076 +0000 UTC m=+80.077325097 robusta関連のPodが下記の通り正常に実行しています。
1. (baas-dev-01:monitoring)~$ kubectl get pod --selector 'app in (robusta-forwarder,robusta-runner)'
2. NAME READY STATUS RESTARTS AGE
3. robusta-forwarder-7df7d89447-twcqv 1/1 Running 0 5m51s
4. robusta-runner-7d4d7dfbc4-9mxsl 1/1 Running 0 5m51s参考までに、2つの Pod AとBを選択するには、上記のselectorオプションを app in (A, B)で実行します。
次はrobustaアラートメッセージを受信するSlackチャネルの設定をします。新しい Slackチャネルを作成して、チャネルの webhook urlを設定します。
次に、Slackで Add apps設定を追加します。 Appsメニューで Incoming WebHooksを選択し、上記で生成したチャネル名を選択します。
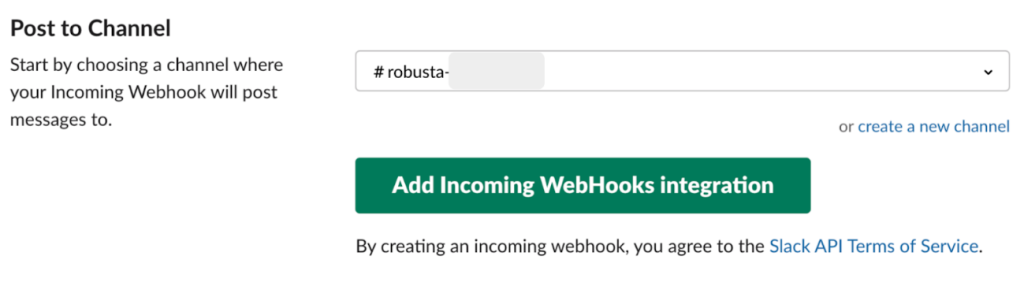
上記のWebhookの設定は下記の Robusta Slackインストール時に使用します。
コマンドプロンプトに次の通り ‘robusta integrations slack’ を入力します。
(jerry-test:monitoring)robusta$ robusta integrations slack
If your browser does not automatically launch, open the below url:
すると、新しいブラウザが開いてSlackのワークスペースを選択する画面が実行されます。この画面で Rubustaがメッセージを転送するチャネルが含まれたワークスペースを選択します。選択が完了すると次の様に Slack IDとSlack keyが確認できます。
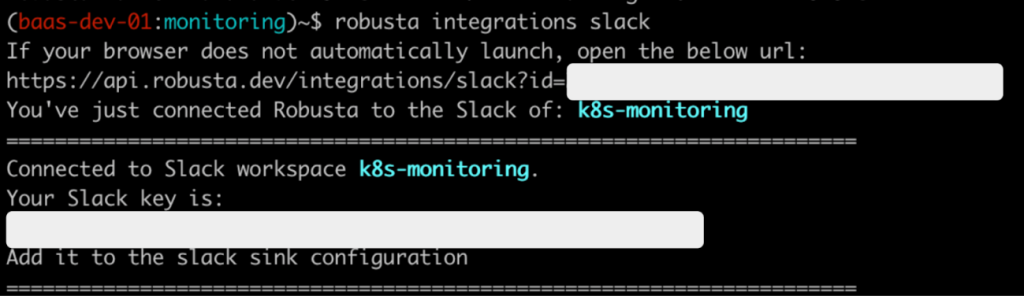
次は生成したRobusta Helm設定ファイル(~/generated_values.yaml)に次の様に Slack関連設定を追加します。
1. sinksConfig:
2. # slack integration params
3. - slack_sink:
4. name: main_slack_sink
5. api_key: MY SLACK KEY
6. slack_channel: MY SLACK CHANNELMY SLACK KEYとMY SLACK CHANNELの情報は設定に合わせて変更します。Helmアップグレード作業を行う前に先ず、設定に異常がないかhelm diffコマンドで確認します。
1. (baas-dev-01:monitoring)robusta-0.10.25$ helm diff upgrade robusta -f ~/generated_values.yaml --set clusterName=baas-dev-01 .
2. monitoring, robusta-playbooks-config-secret, Secret (v1) has changed:
3. # Source: robusta/templates/playbooks-config.yaml
4. apiVersion: v1
5. kind: Secret
6. metadata:
7. name: robusta-playbooks-config-secret
8. namespace: monitoring
9. data:
10. - active_playbooks.yaml: '-------- # (10409 bytes)'
11. + active_playbooks.yaml: '++++++++ # (10559 bytes)'
12. type: Opaque正常にSecret情報がアップデートされ、アップグレードが行われました。
1. (baas-dev-01:monitoring)robusta-0.10.25$ helm upgrade robusta -f ~/generated_values.yaml --set clusterName=baas-dev-01 .
2. Release "robusta" has been upgraded. Happy Helming!
3. (省略)
4.
5. Visit the web UI at: https://platform.robusta.dev/以上で設定が完了しました。
任意でエラーがあるPodを実行してエラーメッセージがSlackに正しく転送されるかを確認します。 Robustaが提供するサンプル Podを使用します。
1. (baas-dev-01:monitoring)~$ k ns default
2. (baas-dev-01:monitoring)~$ kubectl apply -f https://gist.githubusercontent.com/robusta-lab/283609047306dc1f05cf59806ade30b6/rawCrashLoopBackOff状態の Podが実行されます。
1. (baas-dev-01:default)~$ k get pod --selector app=crashpod
2. NAME READY STATUS RESTARTS AGE
3. crashpod-5794b8d86c-258xc 0/1 CrashLoopBackOff 2 (17s ago) 31s
Slackで確認すると、次の様に障害メッセージを確認できます。
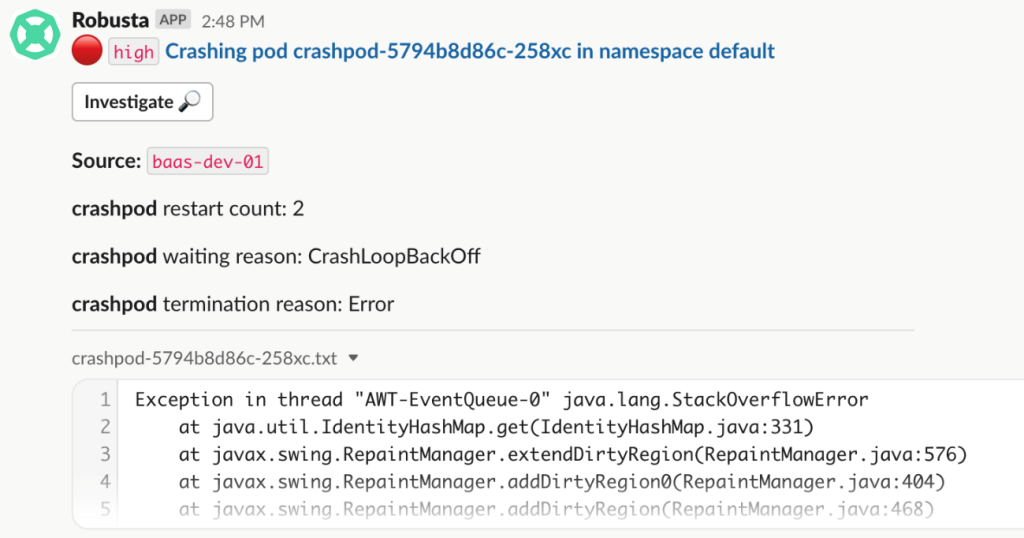
以前のAlertManagerに比べてメッセージが直観的で、メッセージを確認すると直ぐにCrashLoopBackOffエラーであることを確認できます。このメッセージで担当者はより早く障害処理を開始できます。
Robustaは多くの障害事例を Github上に公開しており、下記のサイトでそれらを参照できます。
https://github.com/robusta-dev/kubernetes-demos

Robustaはモニタリング SaaSサービスも提供しています。次のサイトに接続すると便利な UIを確認できます。
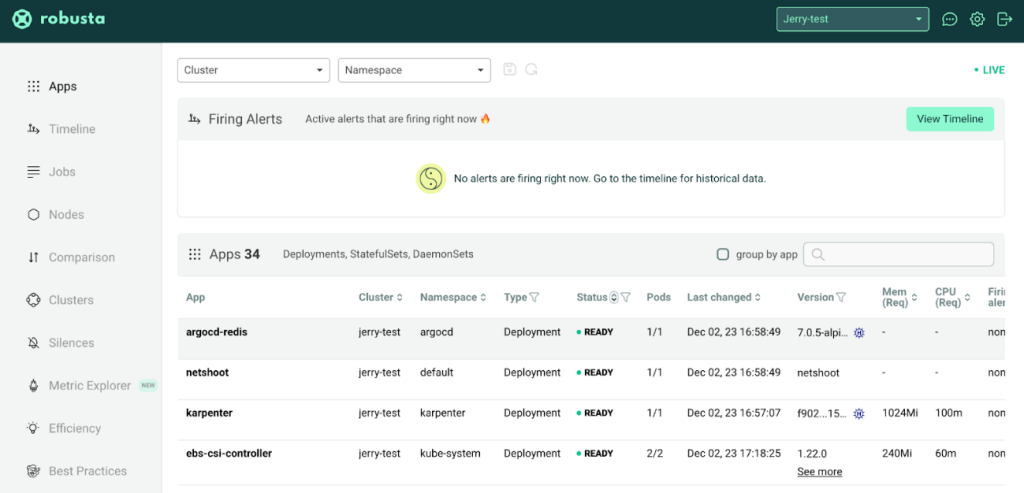
画面左側の Timelineメニューでは、下記の様に時間帯別の障害状況を確認できるため、非常に便利です。
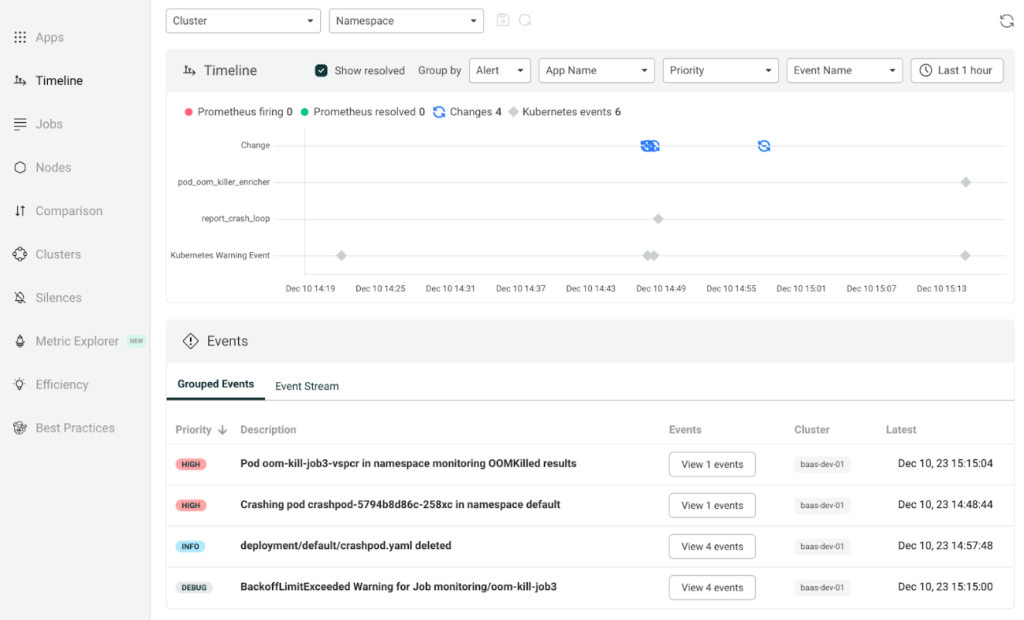
このようにRobustaで直観的なエラーアラートを受信できるため便利です。
テストを完了したら、障害の Podを削除します。
1. (baas-dev-01:default)~$ k delete deployments.apps crashpod
2. deployment.apps "crashpod" deleted
7. Grafanaアラートサービスの設定
運用段階でアプリケーションに関するモニタリングダッシュボードは Grafanaで設定します。Redis、 Kafka等のパブリックアプリケーション以外の自社で開発したインハウスアプリケーションも同じくダッシュボードを作成します。CPU、メモリー等のリソース使用量のみならずコネクション数など Googleの 4つのゴールデンシグナル情報を含めることをお勧めします。
ダッシュボードに関するアラートは Grafanaで直接設定できるので、実際に Grafanaでアラートを設定する方法を確認します。先ず、 Grafanaのアラート関連メニューは下記の様に画面左側にあります。
筆者が使用したGrafanaのバージョンは2023年12月で最新のバージョン10.0.3です。バージョンによりメニューは異なる可能性があります。
1. (jerry-test:monitoring)~$ k describe pod prometheus-grafana-6fbc8d9774-7w58z
2. (省略)
3. Image: docker.io/grafana/grafana:10.0.3このメニューでアラート関連の設定を行います。
先ず、アラートを受信するチャネル、即ちSlack、teams、Eメール等を設定します。Alerting – Contact Points メニューを選択します。
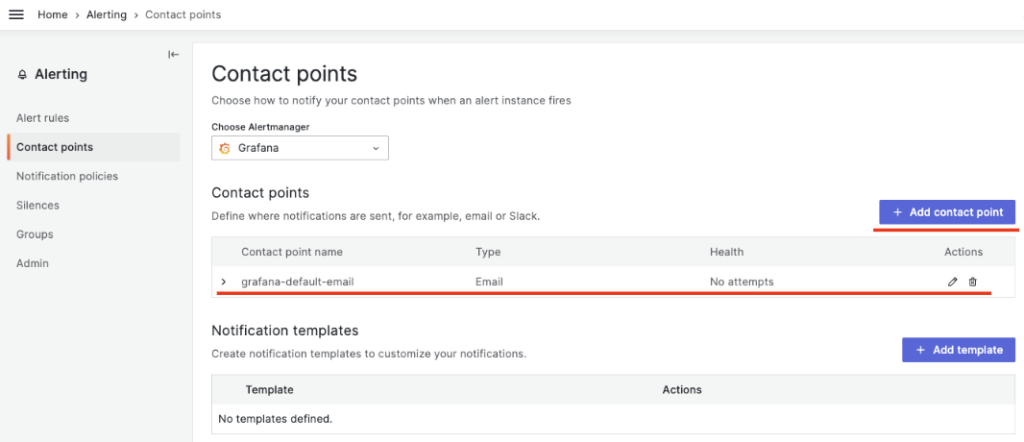
デフォルトでは上記のように grafana-default-emailの設定がされています。筆者はEメールの代わりにSlackを使用します。上段の Add contact pointメニューを選択します。
Grafanaはチャネルを便利に統合できるように、多くのチャネルテンプレートを提供しています。Slackの場合は、 Webhook URLだけ入力すると、設定が簡単に完了します。
アラートを受信するSlackチャネル名は任意に決めて、そのSlackチャネルで Webhook URLを 次の様に入力します。
Webhook URLは Slackで設定します。 Slackメニューの Add appsを選択します。
続きの画面で Incoming WebHooksを選択します。
次のConfigurationメニューを選択すると、新しいページに繋がります。
このページで Grafana Slackアラートを受信するチャネル名を指定します。
すると、次の様にWebhook URLが確認できます。

次に、この URLを上記のGrafana Contact pointsメニューに入力します。
再度、Grafanaに戻ってWebhook URLが正常に設定されているか、Testメニューで確認できます。
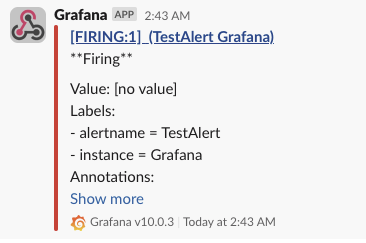
次の様にメッセージが転送されれば、Slackの設定は正常に終了しています。
次に Grafanaで発生するアラートがSlackで転送されるため、Grafanaアラートのデフォルト設定を変更します。Notification policiesメニューで設定します。画面左側の…メニューのEditを選択します。
下記でDefault contact pointを新しく生成したチャネルの Slackに変更します。
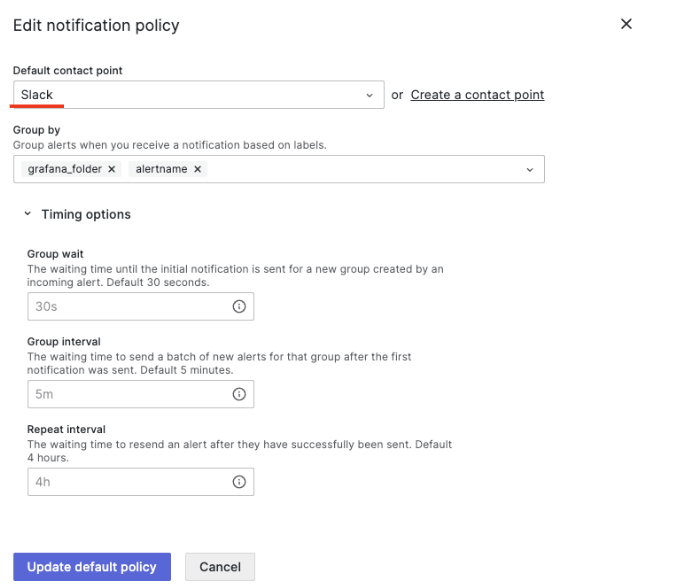
次はテストアラートを設定し、 Slackで正しくアラートが転送されるか確認します。テストアラートは任意に設定できます。筆者は CPU使用率を使用します。テストアラートはアプリケーションダッシュボードを作成した場合、このダッシュボードを基準に作成した方が実際の状況に近いです。
Grafanaのアラート設定はダッシュボードで設定できます。アラート設定が必要なダッシュボードを選択します。筆者は前にインストールした Kubernetes / Views / Global ダッシュボードを選択しました。
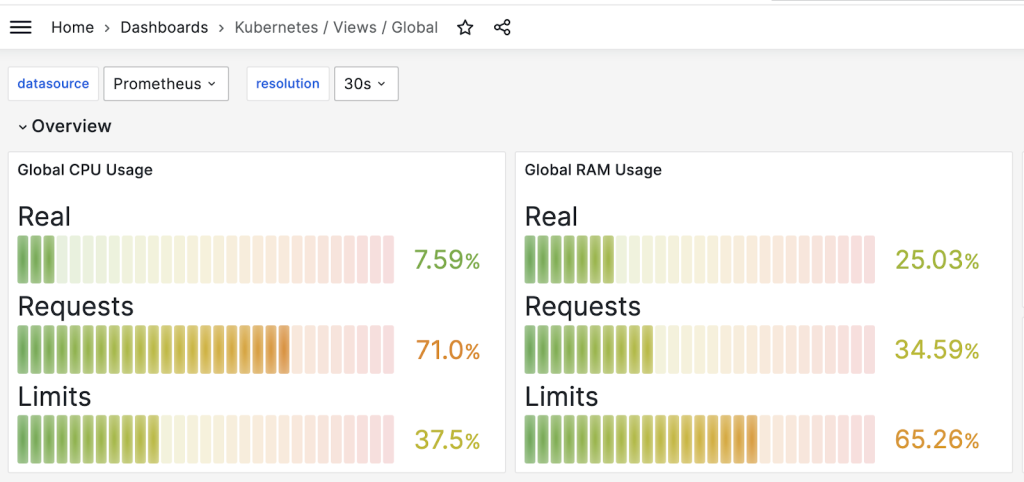
ダッシュボードでノード別 CPU使用率は下記の CPU Utilization by instanceパネルです。アラート設定のために右側上段のメニューで Editを選択します。
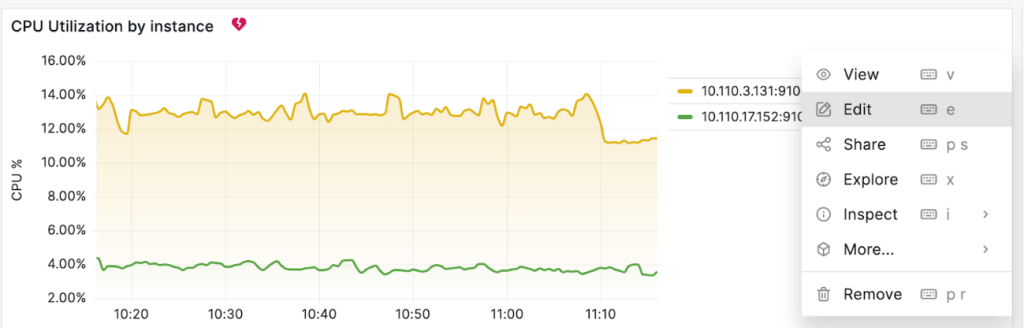
続きの画面で Alertを選択します。そして、 Create alert rule from this panelメニューを選択します。
続きの画面では、アラート関連設定をガイドに従って進めます。先ず、アラート名を任意に設定します。 筆者は CPU使用率が5%以下の場合、アラートを受信する予定のため、下記の様に Low CPU Utilization – 5%を指定しました。

5%以下の場合、アラートを受信するために先ず、項目Bに Thresholdを選択してIS BELOW 0.05を入力します。閾値を基準にアラート設定しますが、Thresholdで0.05とは5%を意味します。
次に項目Cで Reduceの Maxオプションを選択します。最大使用率が5%未満の場合、アラートを受信するように設定します。 Inputは Bで、前に設定した Thresholdの値を指定します。
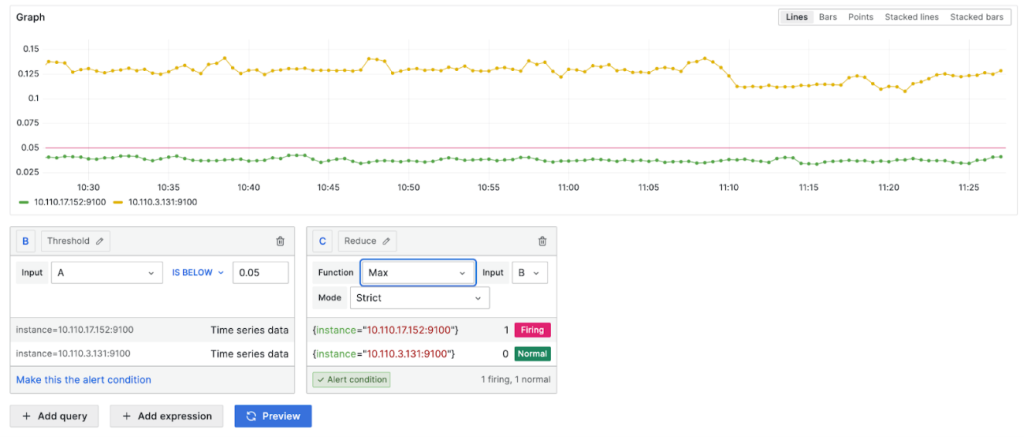
設定を完了してPreviewボタンを選択すると、現在の設定がグラフとFiring、Normalで確認できます。上記の設定で10.110.17.152ノードが5%未満の使用率のため、正常にFiring状態になったことを確認できます。
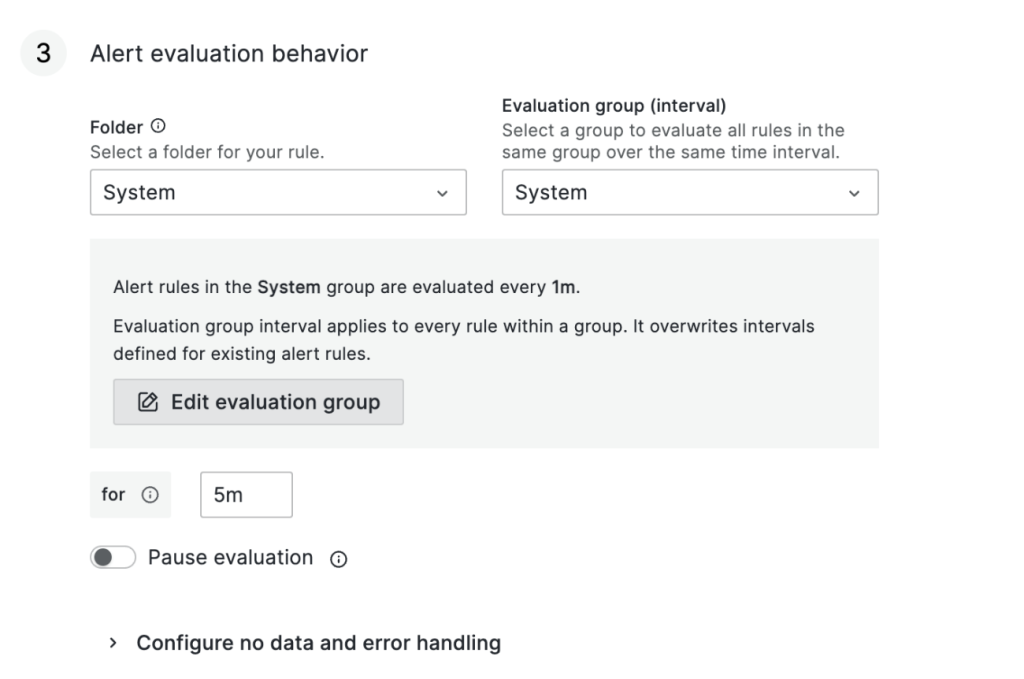
次はアラートの確認周期です。何分間隔 (evaluation)で、どのくらい継続する (for)とアラートを発生するかを設定します。筆者は下記の様に1分間隔で5分間継続するとアラートを発生するように設定しました。
設定が完了したら、画面上段の Save rule and exitをクリックして保存します。
次はAlertメイン画面で下記の様に先ほど設定したSystem > Systemアラートを確認できます。
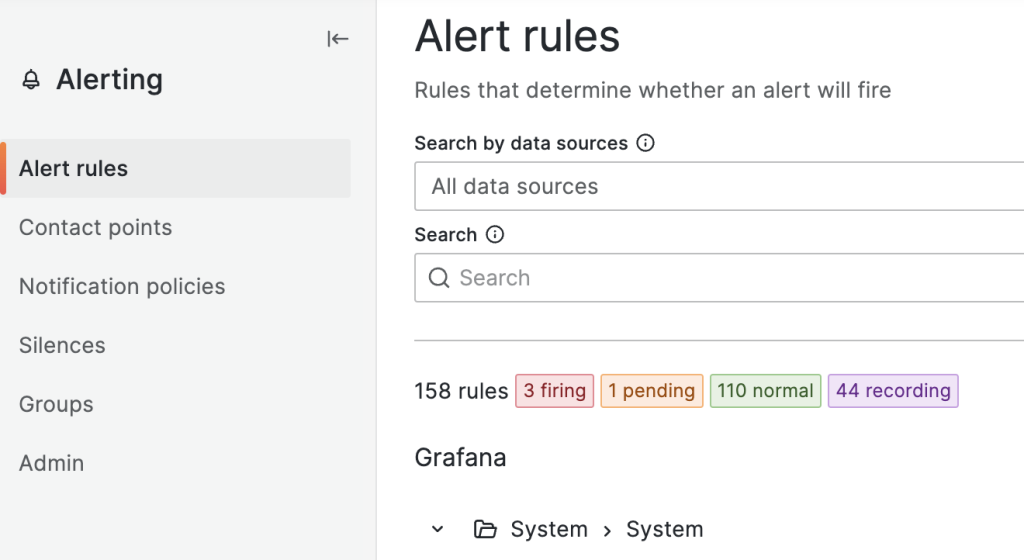
一つのノードの CPU使用率が5%未満で、下記の様に Pending状態を確認でき、設定した5分以上継続するとFiring状態に変更されてアラートを発生します。

5分経過すると下記の様に Slackでメッセージを確認できます。
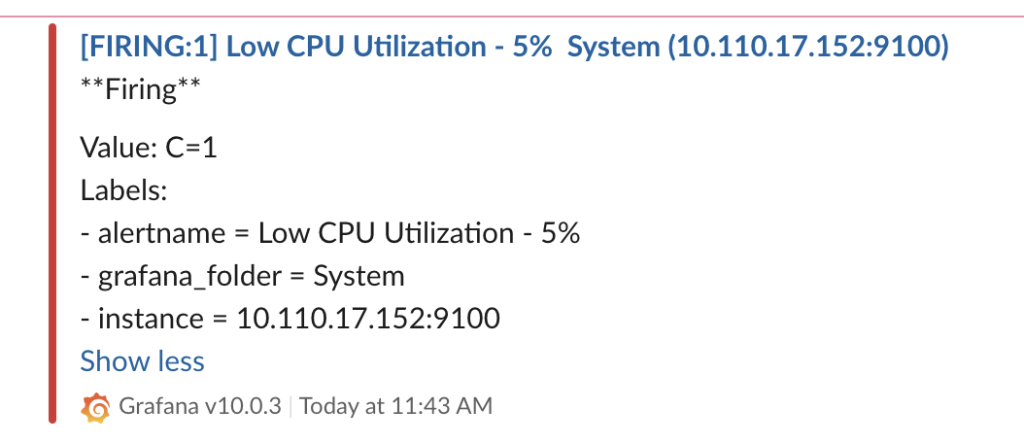
以上 Grafanaでアラート設定する方法を確認しました。実際の運用環境でサービス別のダッシュボードを生成する時に必要なアラートは上記のように設定できます。
今回はクバネティスアラートシステムについて確認しました。先ず、アラートシステムはどのような要件を満足するべきか、これらの要件を満たすために Alertmanager、Robusta、Grafanaでどのように実装するかを実習で確認しました。