
2024年11月08日
連載 第13回
FinOpsの概念と必要性及び実行方法
今回は FinOps(Financial Operations)を確認します。 FinOpsはクラウドコスト管理と最適化をコアとした新しい運用モデルです。クラウド環境で支出を効率的に管理し、最適化するために財務、運用、技術チームの間の協業を強化します。 FinOpsは企業がクラウドコストをより透明、管理可能で、予測可能とすることを目標にしています。
1. FinOpsとは?
FinOps と似た考え方のDevOpsは、開発担当者 (Dev)と運用担当者 (Ops)がSilo(個別チーム単位に隔離された環境)で仕事を行わず、会社の成長という共通の目標で協力する企業文化です。技術的な部分と規範的な部分を含みます。FinOpsも同じです。財務チーム(Fin)と運用チーム (Ops)が互いに協力することを重視する規範的な部分を強調します。この用語は2016年頃にAWSイベントで初めて使用されました。未だ見慣れていない用語ですが、アメリカではある程度一般化されてFinOpsチームが存在する会社もあります。勿論、 FinOps以前にもコスト削減というタイトルは見慣れています。
FinOpsはクラウドコストの可視性と最適化を追求する運用モデルの一つの形態で、技術チームと、ビジネスチーム、財務チームが互いに協業し、クラウドコストの価値を最大化する運用モデルです。このモデルはコスト管理をリアルタイムで実行し、コストの透明性を確保します。クラウド支出に関する持続的な最適化を可能にする慣行、原則とフレームワークを含みます。FinOpsは変化するビジネス要求に合わせてクラウドリソースを素早く、柔軟に調整すると同時に支出の効率性を保証し、コストを賢く管理して企業の戦略的な決定を効果的に遂行できるようにサポートします。
また、DevOpsと同じく財務と運用チームが、互いに協業するための一連の規範やフレームワーク等の技術を含めた、より幅広い概念です。その差は開発チームと運用チームはエンジニアという共通点がありますが、財務チームと運用チームはお互いにバックグラウンドが異なるため、一般的な内容が多く含まれています。
2. 導入背景と必要性
クラウド導入前のオンプレミスのデータセンター環境では、新しいサーバやストレージなどのインフラを購入するには、先ず、財務チームの承認を得なければなりません。大概の会社がそうだと思いますが、私の前の会社も、この承認を得ることが非常に大変でした。最大使用量の予想の根拠を慎重にサイジングし、複数あるソリューションの中で、価格競争力がある最適のソリューションを選択し、複数の見積りを取るなどの長くて難しいプロセスが必要でした。全社の情報戦略の予算の承認には時間がかかり、複雑なために、R&Dチームはこれを回避するため、購入の一部は部門予算を使用することもありました。
企業が伝統的なオンプレミスのインフラから柔軟に拡張できるクラウドサービスへ転換することにより、以前には予測可能であったIT支出が、変動性が高い複雑な構造に変化しました。この変化は既存のコスト管理では効果的に対応できない新しい挑戦でした。クラウドを使用すると、ITコストが既存の投資方式(CapEx)ではなく、毎月使用した従量で課金されるコスト(OpEx)へ変更されました。財務チームは、突然のコスト爆弾の受け取りが発生することもあり、計画を重視する部署であるため、予算を決めないといけないのに予算を決めることが難しいです。
ITコストが増加すると、よく財務チームでは「会社が厳しいので10%以上のコストを削減してください」と言い、技術チームは「コストを削減して障害、セキュリティートラブルが発生したらどうするんですか?」とお互いの意思決定が難しくなります。また、為替レート(円安)の影響でクラウドコストが20%以上高くなることもあります。そのため、FinOpsやコスト削減に関心が高まっています。勿論、コストを統率することは外部環境の変化に関係なく、全ての組織が毎日行う必須課題です。
3. FinOpsの主なメトリクス
FinOpsを実際の業務に導入するために、具体的な方法には中央集中的なクラウドコストの管理体制の構築、リアルタイムモニタリングとアラートシステムの導入、全てのリソースのタグ割当てなど幾つかの方法があります。このような方法を導入する場合の基本原則では、データに基づく意思決定が重要です。FinOpsは財務チーム、事業チーム、開発チーム、運用チームなど異なる背景を持つチーム間のコミュニケーションが重要で、その原則がデータに基づいて意思決定をするということです。
正しいFinOpsの意思決定のためのデータの根幹となる主なメトリクス(指標)はクラウドコストの効率性、使用率、予算遵守など多様な側面があります。次に、主なメトリクスを確認します。
クラスタのCapacityとRequestの比率は?
EKSノードの全体割当て可能なリソース(Capacity)と全体 Podの Request割当て比率を測定します。比率は70%以上を推奨します。クラスタノードのスケールアウトでkarpenterを使用すると、 karpenterが自動的にPodのリソースリクエスト量(Request)に合致する最適のノードを割当て、リソースの余裕があればノードを減らす(Consolidationオプション)作業を進め、比率を推奨値の70%以上にすることが容易です。個人的にはEKS環境では karpenterを使用することを推奨します。
下記の様に eks-node-viewer(または Grafana)などの便利なツールを利用すると、数値を確認できます。

実際の使用量とRequestは適切に設定されているか?
リソースリクエスト量(Request)の設定時に、実際の使用量に関係なく、サービスの安定性を理由に大半のPodに余裕を持たせるため、任意で 1Core、1Giなどの設定をします。その後は、使用量をモニタリングせず、その設定のことを忘れています。
Podのリソースリクエスト量(Request)の設定はコストと直結するため、実際の使用量に基づいて Requestを設定することが大切です。1Coreの設定をしたのに、実際の使用量は0.1Coreも使わないことが頻繫に発生します。 Kubecost、KRR(Kubernetes Resource Recommender)等のツールを使用すると、このような問題の解決に役立ち、個別の運用環境に適合した基準でリソース Requestの基準が設定できます。例えば、 CPUは直近1週間(または1ヶ月)の実際の使用量の90%が基準で、メモリは直近の使用量の最大値 + 10%の余裕値でRequest値を調整して適用できます。このように実際の使用量に基づいてリソースリクエスト量を変更すると、ノードの最適化が可能です。筆者も、このような簡単なサイジング作業でEC2コストを20%以上節約できました。
参考までに、CPUは Requestのみ設定して、Limitは設定せず (Burstable設定) 、メモリは Request/Limitを同じに設定(Guaranteed)にして運用中です。 CPUは時間で使用するリソースのため、Limitの設定をしないことが性能的に有利です(初期起動時のSpikeの発生でReadiness Probe Failの問題の解決等)。
RI/SPの利用率
RI/SP使用率は、予約したインスタンスが実際どの程度使用されているかを表す比率です。つまり、予約インスタンスを購入後に、実際にこれを使用している程度を数値で表します。予約インスタンスは一定期間事前に決済することで、割引価格でコンピューティング容量を確保する方式ですが、購入した全ての予約インスタンスを完全に使用しないと、予想したコスト削減効果を得られません。そのため、RI/SPの利用率が高ければ高いほど予約インスタンスの投資対効果が高いと言えます。90% ~ 100%に維持することを推奨します。
RI/SPカバレージ(予約インスタンスのカバレージ)
カバレージは使用可能な全インスタンスの中で、予約インスタンスでカバーされる比率をいいます。これは単純に複数のインスタンスが予約されたかではなく、使用中の全インスタンスの中で予約インスタンスが占める比率を意味します。このメトリクスは組織が予約インスタンスを十分に活用し、割引の恩恵を最大化しているかを評価することに使用されます。予約インスタンスでカバーできる部分が多ければ多い程、全体コストの削減効果が大きいと考えられます。会社によりますが、筆者は70%程度を維持しながら4半期毎に遊休インスタンスの削除とインスタンスタイプの調整などを行っています。
利用率は、例えば、会社が10個のインスタンスを使用して、その中で5個が予約インスタンスであればRI カバレージは50%です。もし、この5個の予約インスタンスが全体時間の80%を使用するとRI 利用率は80%になります。実際の適用状況はMSPまたは CSP等のプロバイダーが提供するコスト関連のレポートで把握できます。
その他、スポットインスタンス比率、遊休リソース(EBS、ロードバランサー等の全リソースを含む)、タグリソース比率、Cost Optimizer/Trust Advisor等の活用できる多様なメトリクスがあります。全ての推奨事項を一度で適用することは難しいです。一度で適用するとサービス障害等の副作用が発生するため、段階的な適用を推奨します。
このようなメトリクスをモニタリングして、メトリクスを基準にシステムを最適化することは、クラウドコストを効率的に管理して財務的に健全なクラウド運用環境を構築するために重要です。FinOpsチームはこのメトリクスを定期的に検討し、コスト削減の機会を見出すことでコストを最適化できます。
では、FinOps適用時に、活用できる Kubecostツールを実習で確認します。
4. FinOps活用ツールKubecost
Kubecostはクバネティスクラスタで発生するコストをモニタリングし、最適化するオープンソースのツール(OpenCostも使用可能)です。 Kubecostは開発担当者と運用チーム(または財務チーム)がリソースの使用量とコストをリアルタイムで把握し、効率的なコストのインフラを構築できるようにサポートします。
既存の VM環境からコンテナー、クバネティス環境へ移行するとき、VM単位にコストを追跡してコストを計算することは難しいです。単一VM(ワーカーノード)で複数のコンテナーが実行すると、コンテナーは特定 VMに属することなく複数のVMで実行できます。このような制約の下で Kubecostなどのツールを使用すると、 Request割当量基準でコストのモニタリングができ、コストの可視性が向上します。
Kubecostの主なメリットは次の通りです。
• コストの可視性と透明性の提供
• リソース使用量の分析による最適化方法の検討が可能
• 予算超過防止のためのコストアラートの設定が可能
では、実習で詳細を確認します。Helmを利用して Kubecostをインストールします。
1. (jerry-test:default)kubecost$ helm repo add kubecost https://kubecost.github.io/cost-analyzer/
2. "kubecost" has been added to your repositories
3. (jerry-test:default)kubecost$ helm pull kubecost/cost-analyzer --version 1.107.0
4. (jerry-test:default)kubecost$ tar xvfz cost-analyzer-1.107.0.tgz
5. (jerry-test:default)kubecost$ rm -rf cost-analyzer-1.107.0.tgz
6. (jerry-test:default)kubecost$ mv cost-analyzer cost-analyzer-1.107.0
7. (jerry-test:default)kubecost$ cd cost-analyzer-1.107.0/
8. (jerry-test:default)cost-analyzer-1.107.0$ mkdir ci
9. (jerry-test:default)cost-analyzer-1.107.0$ cp values-eks-cost-monitoring.yaml ci/my-values.yaml既存の Helmインストール方法と同じです。バージョンはインストール時点の最新バージョンを使用しても問題ないですが、筆者のテスト環境と同じ構成にする場合はバージョン1.107.3を使用します。インストール時に、上記のように ‘–version 1.107.0’(23年11月基準)とバージョンを明示します。
デフォルトで提供されるHelm Values.yamlファイルで Kubecostが提供するeks環境に適合するように変更した values-eks-cost-monitoring 基盤でciディレクトリにmy-values.yamlファイルを生成します。
my-values.yaml
1. global:
2. prometheus:
3. enabled: true # If false, Prometheus will not be installed -- Warning: Before changing this setting, please read to understand this setting https://docs.kubecost.com/install-and-configure/install/custom-prom
4.
5. grafana:
6. enabled: false
7. proxy: false
8.
9. # Define persistence volume for cost-analyzer
10. persistentVolume:
11. size: 32Gi
12. dbSize: 32.0Gi
13. enabled: true # Note that setting this to false means configurations will be wiped out on pod restart.
14. # storageClass: "-" #
15. # existingClaim: kubecost-cost-analyzer # a claim in the same namespace as kubecost
16.
17. ingress:
18. enabled: false
19. # className: nginx
20. annotations:
21. kubernetes.io/ingress.class: nginx
22. # kubernetes.io/tls-acme: "true"
23. paths: ["/"] # There's no need to route specifically to the pods-- we have an nginx deployed that handles routing
24. hosts:
25. - cost-analyzer.local
26. tls: []
27. # - secretName: cost-analyzer-tls
28. # hosts:
29. # - cost-analyzer.local
30.
31. prometheus:
32. server:
33. image:
34. repository: public.ecr.aws/kubecost/prometheus
35. tag: v2.35.0
36. kube-state-metrics:
37. disabled: false
38. nodeExporter:
39. enabled: falseglobal.prometheus.enabled: true
Kubecost用の別の Prometheusをインストールします。既にインストールしたPrometheusを使用できますが、Kubecostで提供する利便性の高いPrometheusを使用します。
global.grafana.enabled: false
prometheusはインストールしますが、 Grafanaはインストールしてあるものを使用するため、追加でGrafanaはインストールしません。
ingress.enabled: false
テスト環境のため、ingressの設定はしません。ingressを使用せず、kube-proxyを使用してアドミンページに接続します。運用環境では ingressを設定して開発チームも簡単に接続できるように変更します。
prometheus.kube-state-metrics.disabled: false
prometheus.nodeExporter.enabled: false
クラスタモニタリングは既存のインストールした prometheusを使用するため、追加で kube-state-metrics、nodeExporter等をインストールしません。
以上の設定が完了したら、Kubecostをインストールします。
1. (jerry-test:default)cost-analyzer-1.107.0$ helm install kubecost --namespace kubecost --create-namespace -f ci/my-values.yaml .
2. NAME: kubecost
3. LAST DEPLOYED: Sat Nov 4 13:01:40 2023
4. NAMESPACE: kubecost
5. STATUS: deployed
6. REVISION: 1
7. NOTES:
8. --------------------------------------------------
9. Kubecost 1.107.0 has been successfully installed.
10.
11. WARNING: ON EKS v1.23+ INSTALLATION OF EBS-CSI DRIVER IS REQUIRED TO MANAGE PERSISTENT VOLUMES. LEARN MORE HERE: https://docs.kubecost.com/install-and-configure/install/provider-installations/aws-eks-cost-monitoring#prerequisites
12.
13. Please allow 5-10 minutes for Kubecost to gather metrics.
14.
15. When configured, cost reconciliation with cloud provider billing data will have a 48 hour delay.
16.
17. When pods are Ready, you can enable port-forwarding with the following command:
18.
19. kubectl port-forward --namespace kubecost deployment/kubecost-cost-analyzer 9090
20.
21. Then, navigate to http://localhost:9090 in a web browser.
22.
23. Having installation issues? View our Troubleshooting Guide at http://docs.kubecost.com/troubleshoot-installネームスペースを変更して、Helmの状態を確認します。
1. (jerry-test:default)cost-analyzer-1.107.0$ k ns kubecost
2. Context "jerry-test" modified.
3. Active namespace is "kubecost".
4. (jerry-test:kubecost)cost-analyzer-1.107.0$ helm ls
5. NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
6. kubecost kubecost 1 2023-11-04 13:01:40.119878 +0900 KST deployed cost-analyzer-1.107.0 1.107.0 正常にPodが実行しています。
1. (jerry-test:kubecost)cost-analyzer-1.107.0$ k get pod -o wide
2. NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
3. kubecost-cost-analyzer-69b954f664-9cfrg 2/2 Running 0 89s 10.110.27.194 ip-10-110-22-92.ap-northeast-2.compute.internal <none> <none>
4. kubecost-prometheus-server-74bcb9c878-xlc4f 1/1 Running 0 89s 10.110.30.53 ip-10-110-22-92.ap-northeast-2.compute.internal <none> <none>サービス名を指定して、 kube-proxyを実行します。
1. (jerry-test:kubecost)cost-analyzer-1.107.0$ k get svc
2. NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3. kubecost-cost-analyzer ClusterIP 172.20.72.193 <none> 9003/TCP,9090/TCP 2m11s
4. kubecost-prometheus-server ClusterIP 172.20.79.230 <none> 80/TCP 2m11s
5. (jerry-test:kubecost)cost-analyzer-1.107.0$ k port-forward svc/kubecost-cost-analyzer 9090:9090
6. Forwarding from 127.0.0.1:9090 -> 9090
7. Forwarding from [::1]:9090 -> 9090初めての実行では充分なデータが収集できないため、その効果を実感することは難しいですが、1週間程度経過すると意味のあるデータを確認できます。下記は、テストクラスタ環境でPod別の適切な Resource Requestを推奨する機能の事例です。
Resource Requestの割当て時に、実際の使用量を根拠にせず、サービスの安定性向上のために任意に大きく割当てる場合が多いですが、下記の様に実際の使用量を根拠に推奨する使用量が確認できます。
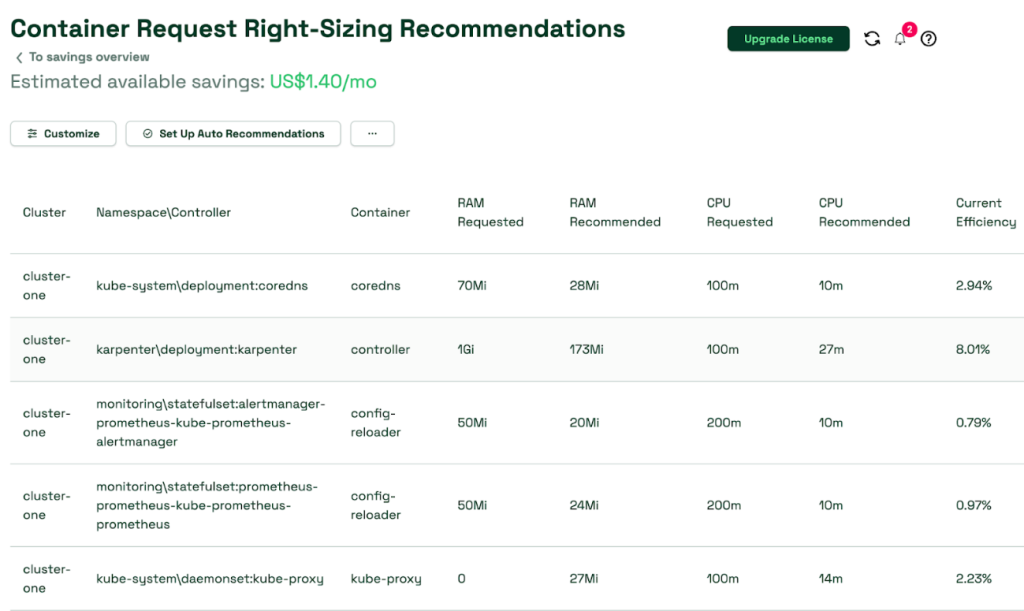
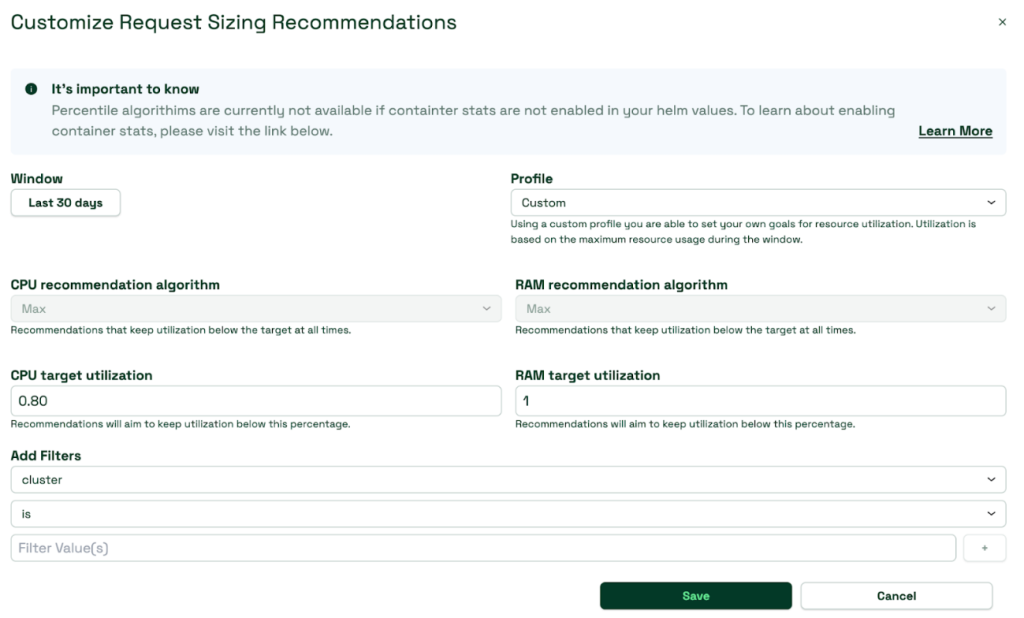
推奨するRequest基準を次の様に各自の環境に合わせて適切に調整すると、より安定的でコストパフォーマンスの高い運用ができます。
クバネティス環境ではアプリケーションが複数のノードに分散して実行され、部署別のコスト割当てが難しいです。この場合、部署別にネームスペースを割当て、各ネームスペースで使用するリソースを基準にコストの割当てができます。 Kubecostを利用すると、次の様にネームスペース別のコストの確認で便利です。
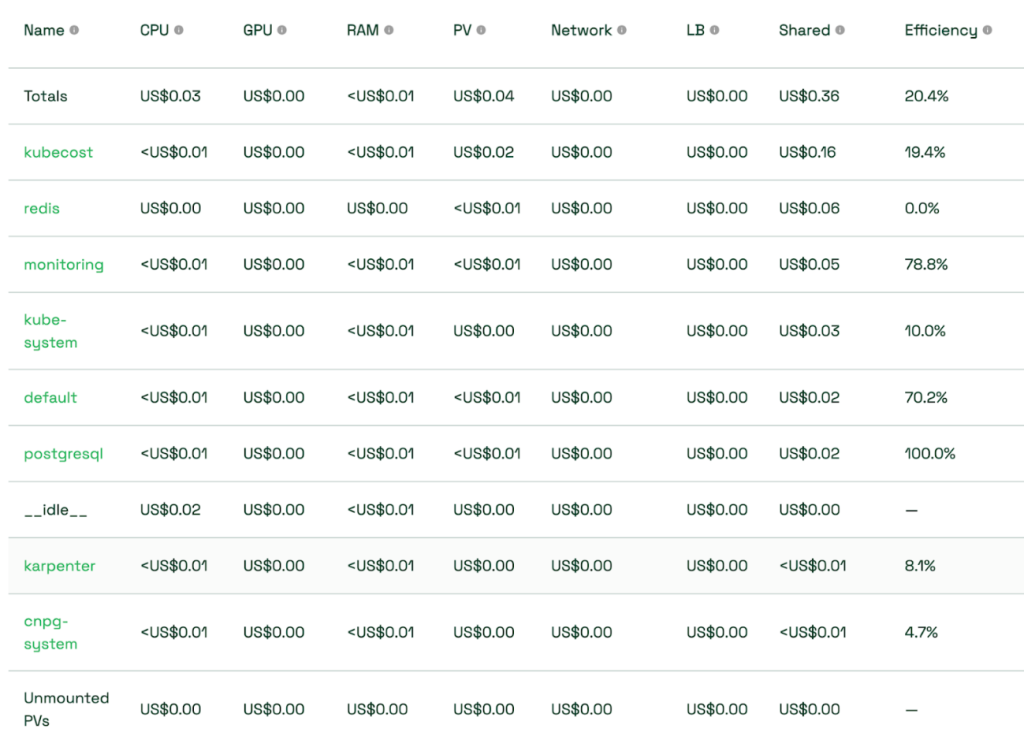
Kubecostは Kubernetesクラスタのコスト管理と最適化に強力なツールです。これはクラスタリソース使用量をリアルタイムでモニタリングし、コストを透明化して、組織のクラウド支出を効果的に管理できるようにします。Kubecostはネームスペース、ラベル(Labels)、またはユーザ定義フィルタで細分化されたコストデータと、コスト削減のための推奨事項を提供し、不要なリソースの使用を最少化することをサポートします。全般的にKubecostは Kubernetes環境でコストの効率性と予算管理の透明性を高める重要なソリューションです。
今回は最近関心の高いFinOpsを確認しました。