
2025年01月10日
連載 第15回
モニタリング
ダッシュボードの構築
今回はモニタリングダッシュボードで使用する Grafanaを確認します。
1. Grafanaの紹介
Grafanaは2014年にTorkel Ödegaardにより開発されて、現在は Grafana Labsで管理しています。このソリューションは多様なデータソースからデータを収集し、視覚化する時に使います。複雑なデータをユーザが分かり易く理解できるグラフとダッシュボードに変換します。
主な特徴は次の通りです。
- 豊富な事例や優れたユーザビリティのインターフェースとカスタマイズ
Grafanaは直観的で優れたユーザビリティのWeb基盤のインターフェースを提供します。これにより、ユーザは複雑なコーディングの知識が無くても簡単にダッシュボードを生成し管理できます。また、公式サイトとコミュニティで簡単に参考にできる多様なダッシュボードを提供しているので、簡単な設定だけで実務で使用できる完成度の高いダッシュボードが使用できます。
前にインストールしたPrometheus-Stack Helmチャートでも既に多様なダッシュボードが組込まれていて、ユーザは新しいダッシュボードを作成しなくてもクバネティスの運用に必要なダッシュボードを利用できます。
- 多様なデータソースとの互換性
Prometheus、InfluxDB、Elasticsearch、MySQL等のような多様なデータソースと互換性があります。この柔軟性により、ユーザは多様な環境とシステムのモニタリングと分析を一つのプラットフォームで進めることができ、複数のデータソースを統合して一つのサイトで中央で集中式にダッシュボードを構成できます。勿論、AWS等のパブリッククラウド関連データも簡単に追加できます。
- 優れたモニタリングとアラートシステム
アラート設定も便利です。システムのモニタリングとアラート機能を提供し、性能問題と異常状態を迅速に把握して対応できるようにサポートします。
Grafanaはエンタープライズバージョンを提供していますが、無料のオープンソースでもこのような機能を十分に活用できます。
では、実際にどのように使用するか実習で確認します。
2. Grafanaサイトへの接続
Grafanaに接続するためのアドレスは、既にインストールした prometheusコミュニティ Helmチャートに含まれています。Helmチャートには多くの構成がパラメータ形式で提供されているので、ユーザは自分の環境に合わせて変数を変更して利用します。
Grafanaのアドレスは次の ingressの設定で確認します。
1. ingress:
2. enabled: true
3. ingressClassName: alb
4. annotations:
5. alb.ingress.kubernetes.io/scheme: internet-facing # internet-facing or internal
6. alb.ingress.kubernetes.io/target-type: ip
7. alb.ingress.kubernetes.io/group.name: sg-external
8. alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
9. alb.ingress.kubernetes.io/ssl-redirect: "443"
10. alb.ingress.kubernetes.io/success-codes: 200-399
11. alb.ingress.kubernetes.io/certificate-arn: ${CERTIFICATE_ARN}
12. external-dns.alpha.kubernetes.io/hostname: ${GRAFANA_HOST}
13. hosts:
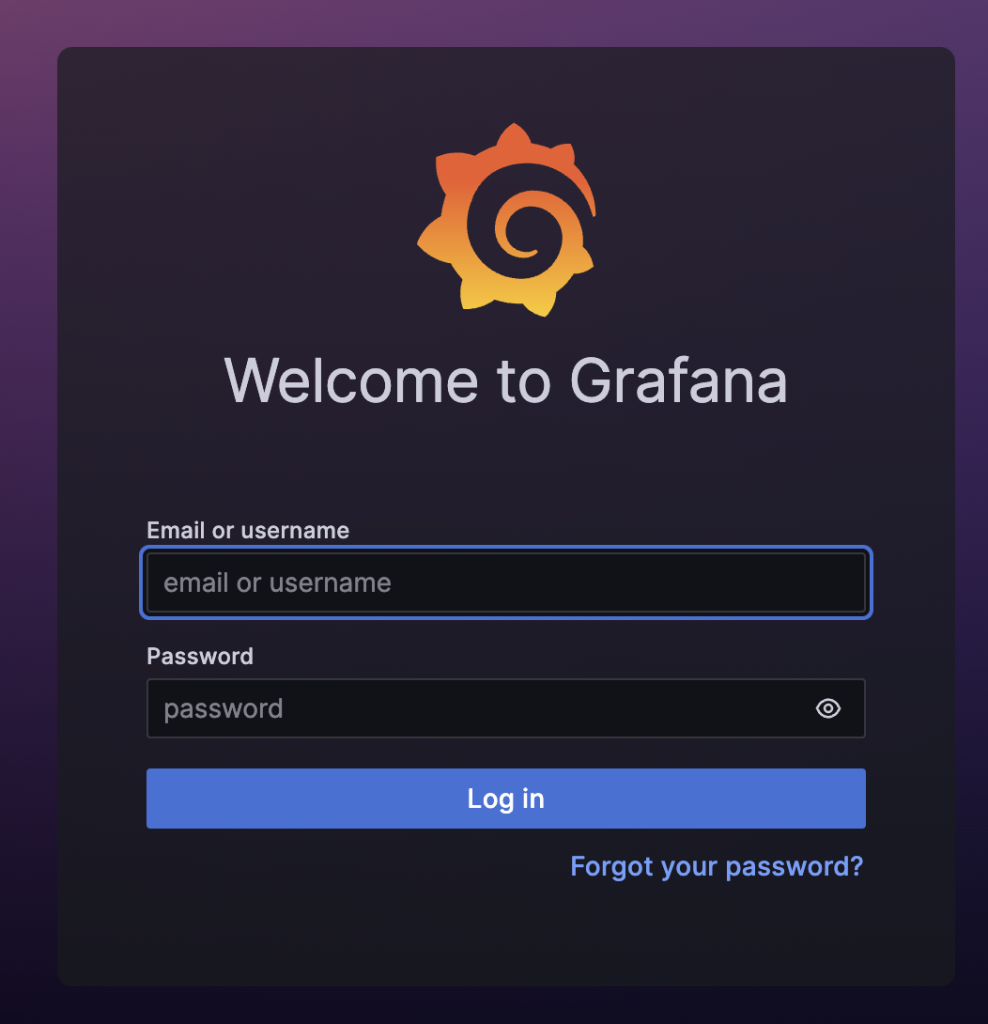
14. - ${GRAFANA_HOST}筆者はセキュリティー上、変数で処理しましたが、$GRAFANA_HOSTが ingressで使用する外部接続アドレスです。このアドレスを External DNSコントローラーが自動でRoute53に登録します。ユーザは Route53でドメインを登録する追加作業はなく、アドレスを入力すれば接続できます。アドレスをブラウザに入力すると、次の様なログイン画面が実行されます。デフォルトIDとパスワードはadmin/prom-operatorです。
パスワード等を変更すると下記の様に Grafana Secret情報で確認できます。K Krewでインストールできる view-secretプラグインを使用すると、パスワードを平文で照会できます。
1. (jerry-test:monitoring)~$ k get secrets prometheus-grafana
2. NAME TYPE DATA AGE
3. prometheus-grafana Opaque 3 24h
4. (jerry-test:monitoring)~$ k view-secret prometheus-grafana admin-password
5. prom-operator3. prometheusコミュニティ Helmチャートダッシュボードの確認
では、ダッシュボードを確認します。 Grafanaが非常に有用な訳は、ユーザ層が広いため、実務で使用できる豊富なコンテンツと際立ったデザインのダッシュボードを無料で提供していることです。実務でモニタリングダッシュボードを作成することは難しい作業です。複数のユーザ (特に上司^^)の好みに合わせたダッシュボードを作成することは非常に難しいです。しかし、 Grafanaは多様なダッシュボードが既に組込まれているために、作る必要がなく既存のダッシュボードを使用できることが大きなメリットです。
ダッシュボードメニューは画面左側で確認できます。
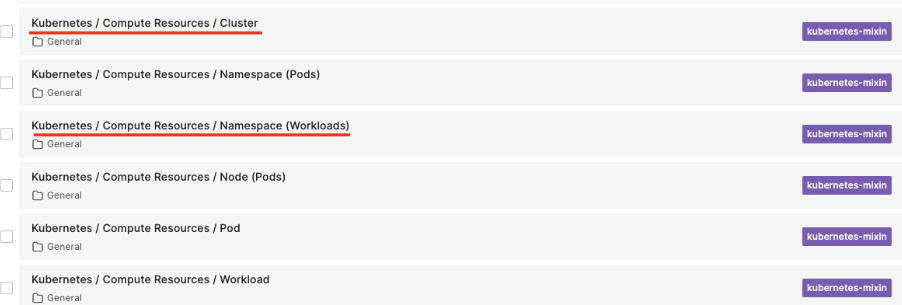
メニューからダッシュボードを選択すると下記の様に Generalフォルダを確認できます。フォルダには prometheusコミュニティ Helmチャートのインストール時に、デフォルトで提供する多様なダッシュボードが組込まれています。

クリックして確認すると多様なダッシュボードがあります。インストールのタイミングで異なりますがデフォルトで20個以上のダッシュボードが提供されています。各ダッシュボードは使い易く、用途も異なるため、要求事項を一つずつ確認しながら必要なダッシュボードを使用できます。
DevOpsの立場で筆者が主に参照するダッシュボードは次の2つです。
- Kubernetes / Compute Resources / Cluster
- Kubernetes / Compute Resources / Namespace (Workloads)
ブックマークに登録すると次回からは簡単に利用できます。
2つ目の Namespaces(Workloads)ダッシュボードは各ネームスペースの特定ワークロード(Deployment、Statefulset等)単位に分類してあり、必要な Podのリソース使用量等を素早く確認できます。
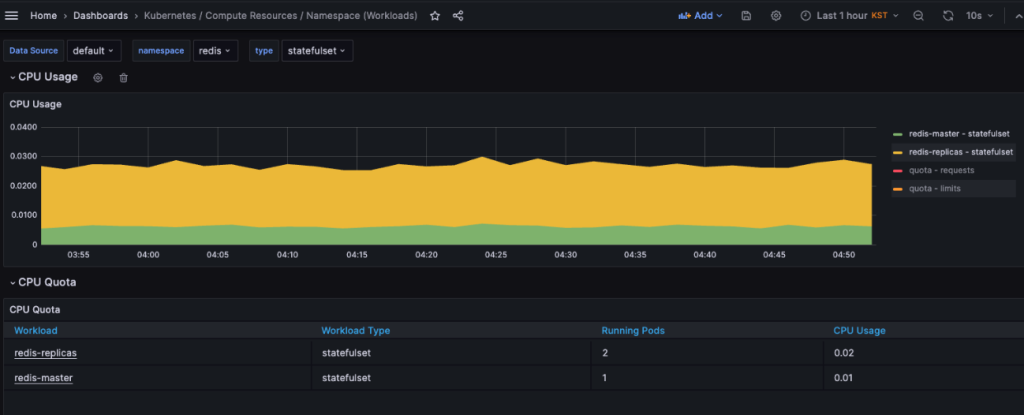
では、追加したダッシュボードを確認する前にモニタリングダッシュボードに関する簡単な質問をします。
何故、ダッシュボードが必要か? ダッシュボードにはどのような情報が含まれるべきか?
これには複数の解答があり、解答毎に妥当な理由があるので正解は一つだけではありません。各解答には全て長所と短所があります。ダッシュボードに関する筆者の意見は1)現在のサービスの状況を客観的な数字のデータで早く把握する、2)障害発生時に、素早く対処できる、3)障害予防の計画を立てるためのダッシュボードが必要と考えています。
関連してGoogleは主なモニタリング項目の要素を次の4つのゴールドシクナル(Golden-Signals)に選定して公表しています。
- 応答速度(Latency)
ユーザリクエストに応答する所要時間
- トラフィック(Traffic)
サービス使用量(例:HTTP requests per second)
- エラー(Errors)
単純エラー以外に、内部応答目標時間を10秒以上遅延したリクエストを含むエラー数
- 飽和度(Saturation)
トラフィック増加またはノード障害等の状態で、予備ノードで処理可能なシステムリソース使用率
基本的な内容ですが、単純にハードウェア側のCPU、メモリ使用量の状況だけを把握することではなく、アプリケーション側の応答速度とトラフィック使用量等のモニタリングを強調しています。管理者目線ではなく、実際にユーザがどのように感じるかがより重要な要素です。ダッシュボードの設計時に、上記のような要素を考慮し、事前に主なページリストを選定し、目標応答時間とユーザ数等のモニタリング項目をサービス担当者と協議して慎重に定義することが大切です。ダッシュボードを作る時は、上司が見易いページを作ることに専念することは避けるべきでしょう。
また、ダッシュボードを作る時は明確な目標を決めて、できる限り簡単で正確な質問に答えられるような直観的なダッシュボードが必要です。そして、ダッシュボードの数はできる限り少なくし、原因となる問題を素早く探すことができて、重複したダッシュボードを作らないように周期的に見直すことも必要です。
大概、CPUとメモリ使用量のダッシュボードを作成しますが、MSA環境でサービスが小さく区分されるほど、サービス開発担当者は担当するサービスの応答速度、使用量、障害の可否、リソース使用量等を含む個別のダッシュボードを準備する努力が必要です。
4. Grafana公式ホームページのダッシュボード共有サイト
ところで、事前に組込まれていないダッシュボードはどのように探すのでしょうか?幸いにもGrafanaは次の公式ホームページでダッシュボード共有サイトを提供していて、世界中の多くのユーザがベストプラクティスインフラのダッシュボードを共有できます。
https://grafana.com/grafana/dashboards/
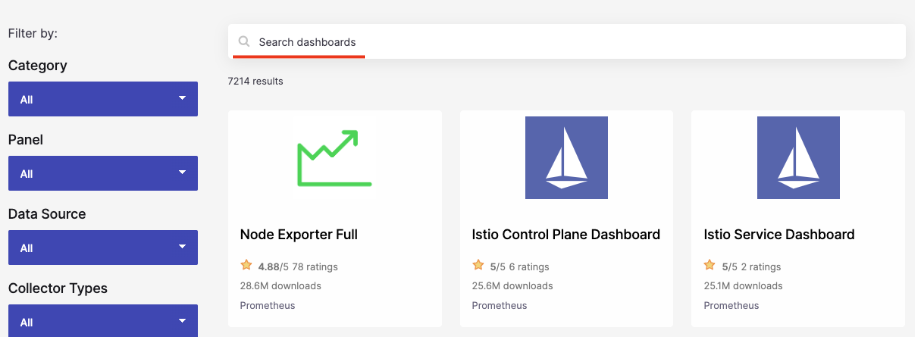
使用方法はそれぞれの目的のアプリケーション、例えば、 Kafka、Redis、MySQLなどの必要なダッシュボードを検索して使用します。プレビュー、照会数、ポイント等を参考にして必要なダッシュボードを選択し、利用します。筆者が推奨するダッシュボードは下記の dotdcユーザが提供するダッシュボードです。
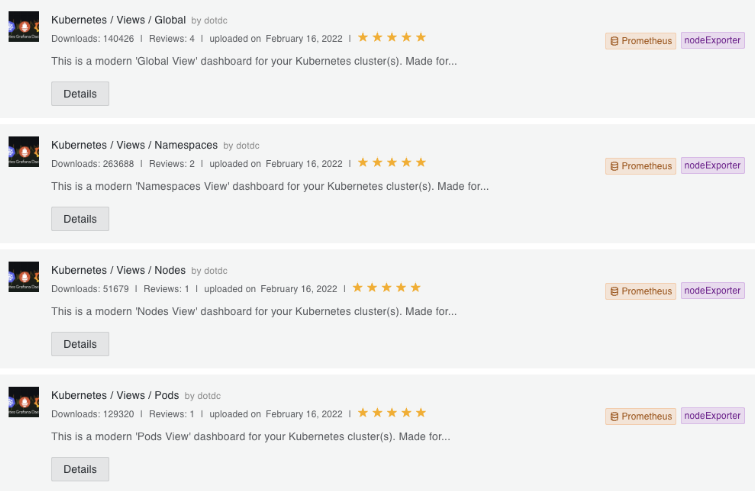
4つの‘Kubernetes / Views /’で始まるダッシュボードを筆者は内部にインストールして頻繁に利用します。上記の画面で ‘Kubernetes / Views / Global ’ダッシュボードを選択すると次の様にプレビューと該当ダッシュボードのID:15757を確認できます。

IDを利用して内部にインストールしたGrafanaにインポート (Import)できます。
Grafanaダッシュボードメニューで New – Importを選択します。
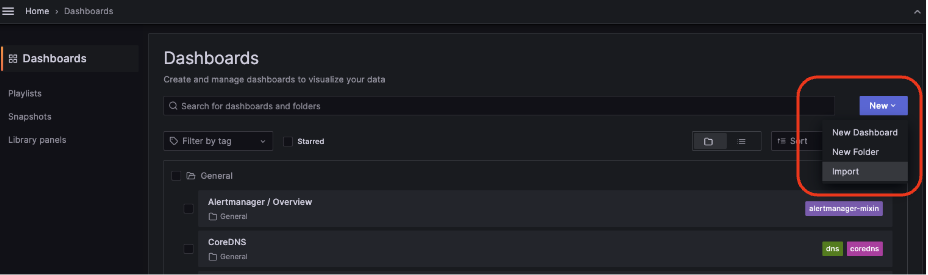
続きの画面で前に確認したIDを入力します。
すると、簡単にそのダッシュボードをインポートできます。ダッシュボードはクラスターサービスの状況を表します。デザインも優れていて直観的に必要な次の情報を分かり易く表示します。
- 全体ノード、ネームスペース、Pod数等のクラスター全般の情報
- クラスターリソースの効率性 – 全体クラスターのリソース容量(Total)、実際のリソース使用率(Real)、Requests、Limits情報(%)を提供
- 時間帯別 ConfigMap、Containers、Secrets等の変化量のヒストリー情報の提供
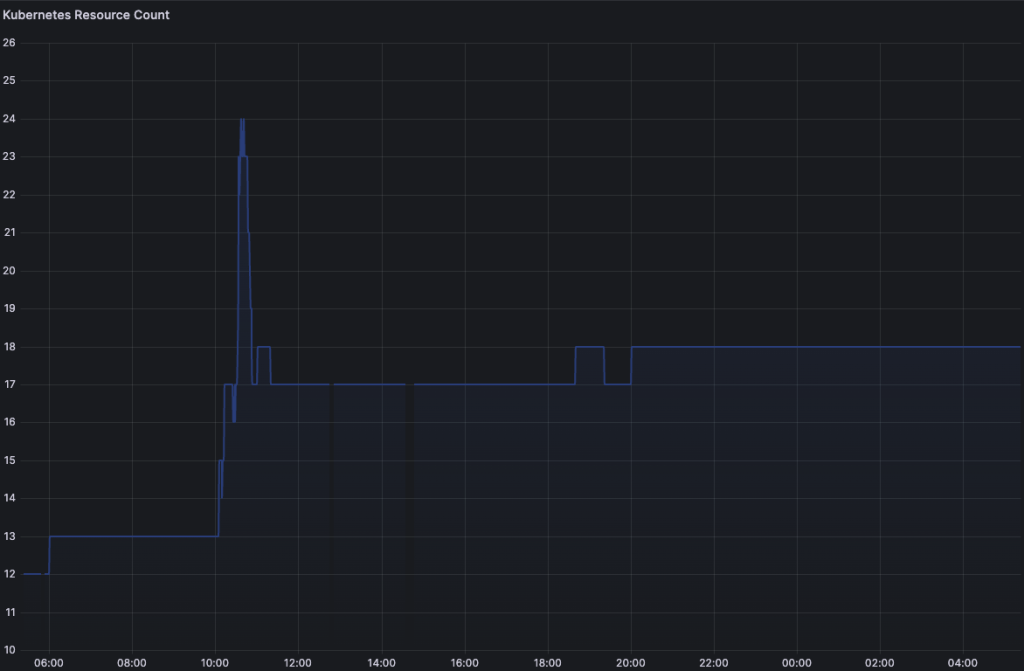
クラスターで Karpenter、HPA、KEDA等のオートスケールシステムを運用すると、時間帯別リソース使用量の変化を頻繁に確認することが必要です。この時、下記の様に時間帯別ノード数の変化量を確認できるので、どのイベントがあるかを確認する時に役立ちます。
同様にネームスペース、ノード、Pod等の状況を把握する時に4つのダッシュボードで様々な使い方ができます。筆者もこの4つのダッシュボードを利用して多くの問題を解決しています。
このように多様なダッシュボードを ID入力のみで便利にインポートできます。
5. ダッシュボードの追加 (prometheus Helmチャートを含む)
では、前述のダッシュボードの インポートを GUIで IDを指定して追加する方法ではなく、Helmチャートに組込む方法を紹介します。実業務ではEKSクラスターを10個以上運用する場面が頻繫に発生します。その時に一々ダッシュボードを手動で追加することは面倒です。何よりクラスター関連の全ての設定は GUIまたはコマンドではなくコードに組込むことがヒューマンエラーを減らす方法です。
前にインストールした prometheus-コミュニティ Helmチャートの Values.yamlファイルに下記の Grafana – dashboard関連の設定を追加します。
1. grafana:
2. enabled: true
3.
4. dashboardProviders:
5. dashboardproviders.yaml:
6. apiVersion: 1
7. providers:
8. - name: provider-site
9. orgId: 1
10. folder: ''
11. type: file
12. disableDeletion: false
13. editable: true
14. options:
15. path: /var/lib/grafana/dashboards/provider-site
16.
17. # now using that provider to import dashboards
18. dashboards:
19. provider-site:
20. kubernetes-views-global:
21. # url: https://grafana.com/api/dashboards/1860/revisions/27/download
22. gnetId: 15757
23. revision: 31
24. datasource: Prometheus
25. kubernetes-views-namespaces:
26. gnetId: 15758
27. revision: 27
28. datasource: Prometheus
29. kubernetes-views-nodes:
30. gnetId: 15759
31. revision: 19
32. datasource: Prometheus
33. kubernetes-views-pods:
34. gnetId: 15760
35. revision: 22
36. datasource: Prometheus
37. prometheus:
38. gnetId: 19105
39. revision: 1
40. datasource: Prometheus
主な設定は次の通りです。
.grafana.dashboardProviders
ダッシュボードを追加するにはConfigMap構成が必要です。該当構成にdashboardProvidersの設定が必要です。任意の名前(provider-site)を指定して設定を追加します。
. grafana.dashboards.provider-site.kubernetes-views-global
gnetId: ‘15757’, revision: ‘31’
前に確認した Grafanaサイトで必要なダッシュボードの IDとRevisionを入力します。詳細ページでIDとRevisionを確認して入力します。複数のダッシュボードの IDとRevisionを入力すると一回でインポートできます。
Grafanaはこの設定を ConfigMapで読み、APIでGrafanaサイトのダッシュボードを呼び出し、ダッシュボードを生成する仕組みです。
1. (jerry-test:monitoring)~$ k describe cm prometheus-grafana
2. (中略)
3. download_dashboards.sh: |
4. #!/usr/bin/env sh
5. set -euf
6. mkdir -p /var/lib/grafana/dashboards/provider-site
7.
8. curl -skf \
9. --connect-timeout 60 \
10. --max-time 60 \
11. -H "Accept: application/json" \
12. -H "Content-Type: application/json;charset=UTF-8" \
13. + "https://grafana.com/api/dashboards/15757/revisions/31/download" \
14. + | sed '/-- .* --/! s/"datasource":.*,/"datasource": "Prometheus",/g' \
15. + > "/var/lib/grafana/dashboards/provider-site/kubernetes-views-global.json"
次は変更したValuesファイルで Helmチャートをアップグレード(helm upgrade prometheus)すると、設定で追加したダッシュボードを Grafanaサイトで確認できます。
Grafanaは未だダッシュボードをカスタマイズリソース(CR)で提供していないため、上記のように Helmチャートで、手動で追加する作業が必要です。少し面倒な点は、ダッシュボードがConfigMapの設定であるため、ダッシュボードを直接変更することはできません。
変更が必要な場合はダッシュボードを JSON形態でダウンロードして修正後、再度アップロードする必要があります。
6. ダッシュボードのデータソース
Grafanaはデータ視覚化ソリューションで、データは Prometheusが提供します。簡単に図で表すと次の通りです。
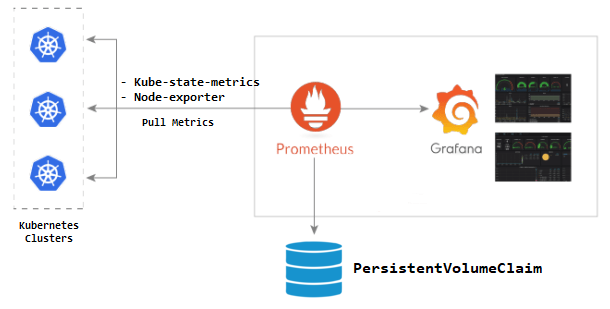
Grafanaのデータソースの設定は画面左側の Connectionsメニューで確認できます。
Connectionsメニューを選択して次の画面で Data sourcesを選択します。
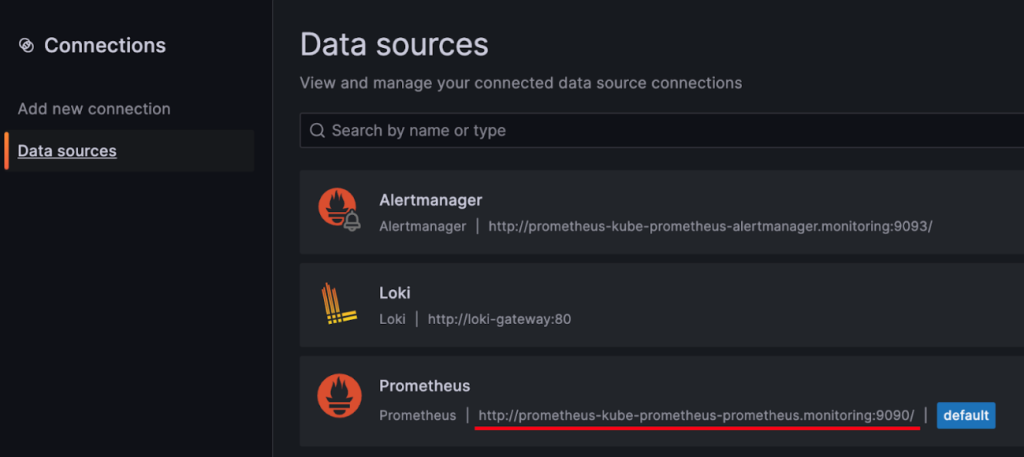
画面上には Prometheusデータソースを確認できます。特に追加の設定作業を行っていませんが、prometheus情報が入力されています。prometheusコミュニティ Helmチャートでこの設定が自動的に組込まれているからです。
prometheusアドレスを確認すると‘http://prometheus-kube-prometheus-prometheus.monitoring:9090’です。これは prometheusサービス名と同じです。クラスター内部でPod間の通信時に、サービス名を利用して通信するためです。 Grafanaは prometheusのサービス名で呼び出します。
1. (jerry-test:monitoring)~$ k get svc prometheus-kube-prometheus-prometheus
2. NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3. prometheus-kube-prometheus-prometheus ClusterIP 172.20.128.66 <none> 9090/TCP,8080/TCP 2d10h
今回は実習を通して Grafanaを紹介しました。 Grafanaの利便性と柔軟性をご自身で体験してください。
Grafanaは複雑なデータを視覚化してモニタリングする時に非常に優れているので、Grafanaを活用してシステム運用と関連データをより直観的で素早く理解することに活用してください。最後に、常に新機能とアップデートに留意してGrafanaの最新トレンドを確認してください。
1. Grafanaの歴史– https://en.wikipedia.org/wiki/Grafana#:~:text=History%20Grafana%20was%20first%20released,12
2. Google SREハンドブック– 4 Golden Signals https://sre.google/sre-book/monitoring-distributed-systems/#xref_monitoring_golden-signals
3. ダッシュボードの模範的事例 https://grafana.com/docs/grafana/latest/best-practices/best-practices-for-creating-dashboards/#best-practices-to-follow