
2024年12月09日
連載 第14回
Kubernetesモニタリングシステム
prometheus

今回はオープンソースモニタリングシステムprometheusを確認します。本題に入る前に、クバネティス環境のモニタリングは、伝統的なVM(仮想マシン)環境のモニタリングとどのような違いがあるかを確認します。既存の環境との違いが分かればより理解し易いと思います。
- 動的環境:クバネティスはコンテナー化されたアプリケーションを動的にスケジューリングして管理します。何故ならPodの生成、消滅、移動が既存の VMに比べて非常に頻繁に行われるため、リアルタイムで変化するリソースとネットワークトポロジーをモニタリングする必要があります。
- サービスメトリクス:クバネティス環境のモニタリングの単位はPodが基本で、アプリケーションプロセスを意味します。そのため、基本単位がVM(OS単位)環境に比べて、よりアプリケーションとマイクロサービスレベルのメトリクスが重要で、サービス応答時間、エラー率、トラフィックパターン等のメトリクスのモニタリングが必要です。
- クラスターの状態:VM単位ではなく全体クバネティスクラスターのヘルス、ノード状態、クラスターリソース使用量等を持続的にモニタリングする必要があります。クバネティスはオーケストレーションと自動化機能を提供しますが、スケーリング、自動回復(Self-Healing)等の動作をモニタリングする事を含みます。
このような要素を考慮してモニタリングソリューションを選定し、クバネティス環境に適合したソリューションを運用する必要があります。
1. prometheusの主な特徴
Prometheusは2018年 8月にKubernetesに続き、2番目に成熟度が一定の段階に達したことを意味するCNCFの卒業プロジェクトで、実質上、クバネティス環境のオープンソースモニタリングの標準ソリューションとなりました。 Prometheusプロジェクトは SoundCloudで初めて構築されてオープンソース公開後に多くの企業や組織で採択され、活発な開発者の活動とユーザコミュニティを形成しました。
クバネティスモニタリングソリューションはオープンソース(prometheus等)と商用のベンダー製品に分類できます。モニタリングはサービス運用部分で最も重要で、個別環境により要求事項も異なるため、導入部門に適合したソリューションを選択します。
では、簡単に prometheusの主な特徴を確認します。
- 統合が容易で運用が簡単
Kubernetesのようなコンテナーオーケストレーションシステムとの統合が容易で、インストールと運用が簡単でITインフラのモニタリングと管理を単純化します。デフォルトの構成要素でのインストールのみならず、モニタリングダッシュボード、アラートルールまで全て単一のHelmチャートを利用してインストールができ、非常に強力です。
- サービスディスカバリー
動的に拡張や縮小ができるクバネティス環境で prometheusは個別のモニタリング対象をサービスエンドポイントに登録すると、自動で変更内容を検知します。サービスリソースを生成すると、自動でエンドポイントオブジェクトが登録され、そのエンドポイントをprometheusがモニタリングします。
- 多様なアプリケーションエキスパート(experter)の提供
MySQL、Elastic、Kafka、Redis等ほぼ全てのアプリケーションが、 prometheusで使用できるメトリクス情報を提供します。ユーザはアプリケーションのインストール時に、追加作業が不要でエキスパートを利用して簡単にモニタリングできます。
- 独自検索言語 PromQL(Prometheus Query Language)の提供
多様なラベル(Labels)の使用が可能なメトリクスを照会できるように、prometheusは独自の検索言語を提供します。PromQLで多様に資料を照会し、視覚化ソリューション Grafanaで必要なグラフ形態で表示します。また、ロギングソリューションの Lokiでも似た検索言語(LogQL)の利便性が優れています。
- コミュニティと統合によるサポート
強力なコミュニティのサポートと多様なサードパーティの統合により、新しい技術とプラットフォームで持続的な拡張したサポートをしています。
- ユーザ要求への柔軟な対応
ユーザの特定要求に合わせてアラート規則、データの収集方法、保存期間等をカスタマイズ設定できるため、多様な環境と要求事項に柔軟に対応できます。
- Pull方式
変更の多い個別のモニタリング対象を prometheusはインストールしたエージェントが中央サーバでモニタリング情報を発生させる (Push)方式ではなく、中央の prometheusサーバがモニタリング情報を直接採取する (Pull)方式です。
モニタリングまたは可観測性(オブザーバビリティ:Observability)に必要な要素は概ねメトリクス、ログ、トレーシング(追跡)がありますが、prometheusはメトリクスのモニタリングソリューションです。モニタリングで使用するメトリクスとは一般的に時系列データで収集されて、ITインフラの性能と関連する多様な側面を定量的に表す時に重要な役割をします。Webサーバリクエスト回数、アクティブ DBクエリ等のアプリケーションの性能は数字で表されたメトリクスで把握できます。例えば、ユーザ応答速度が遅くなった時、管理者は Webサーバリクエスト数が増加するメトリクスを確認し、原因を素早く把握できます。
メトリクスは時間の経過と共に収集されて、システム性能の変化、問題の発生パターン等を時間の経過で分析できます。必要なメトリクスを基準に正常な範囲を定義して、その範囲を逸脱したらアラートを発生させ、問題を迅速に検知して対応できます。管理者はメトリクスを分析することでシステム性能のボトルネックを把握し、問題を解決して全体性能を最適化できます。モニタリングシステムはメトリクスをダッシュボードやグラフ形態で視覚化し、システムの状態を分かり易く把握することで、長期的な推移を分析できます。
クバネティス環境でprometheusを簡単に使用するために、 prometheusコミュニティは prometheusスタック Helmチャートを提供しています。Prometheusのインストールに必要で多様なクバネティスマニフェスト、システムのメトリクスを視覚化してモニタリングする Grafanaダッシュボード、データ収集と処理やアラート生成等を行う prometheus ルール、prometheusスタックのインストール、設定、運用に必要なドキュメントとスクリプト、クバネティスクラスター内で prometheus構成要素を管理する prometheusオペレータまで多様なコンポーネントが含まれています。
実際、モニタリングシステムを構築するには長い時間と熱意が必要ですが、prometheusスタック Helmチャートを使用すると、簡単に構築できます。非常に大きなメリットです。
実習課題:
• Prometheus-Stack Helmのインストール
• Prometheus Node-Exporter構造の確認
• アプリケーションダッシュボード構築 – Redis Exporterの利用
今回の実習で使用するソースファイルのGitHubディレクトリは次の通りです。
• https://github.com/junghoon2/k8s-class/tree/main/prometheus/kube-prometheus-stack-48.3.1
2. Helm prometheusのインストール
では、実習で詳細を確認します。Helmを利用したアプリケーションのインストール方法は以前、説明しました。今回はコマンドのみ記述します。
1. (jerry-test:kubecost)~$ cd k8s-class/prometheus/
2. (jerry-test:kubecost)prometheus$ helm pull prometheus-community/kube-prometheus-stack
3. (jerry-test:kubecost)prometheus$ tar xvfz kube-prometheus-stack-48.3.1.tgz
4. (jerry-test:kubecost)prometheus$ rm -rf kube-prometheus-stack-48.3.1.tgz
5. (jerry-test:kubecost)prometheus$ mv kube-prometheus-stack kube-prometheus-stack-48.3.1
6. (jerry-test:kubecost)prometheus$ cd kube-prometheus-stack-48.3.1/
7. (jerry-test:kubecost)prometheus$ mkdir ci && cp values.yaml ci/コピーしたHelm values.yamlファイルを次の様に変更します。
1. grafana:
2. enabled: true
3. defaultDashboardsTimezone: Asia/Seoul
4. ingress:
5. enabled: true
6. ingressClassName: alb
7. annotations:
8. alb.ingress.kubernetes.io/scheme: internet-facing # or internal
9. alb.ingress.kubernetes.io/target-type: ip
10. alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
11. alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
12. alb.ingress.kubernetes.io/success-codes: 200-399
13. alb.ingress.kubernetes.io/group.name: "my-test"
14. external-dns.alpha.kubernetes.io/hostname: $GRAFANA_DOMAIN
15. hosts:
16. - $GRAFANA_DOMAIN
17. paths:
18. - /*
19. persistence:
20. type: pvc
21. enabled: true
22. accessModes:
23. - ReadWriteOnce
24. size: 10Gi
25.
26. prometheus:
27. prometheusSpec:
28. serviceMonitorSelectorNilUsesHelmValues: false
29. retention: 5d
30. retentionSize: 10GiB
31. storageSpec:
32. volumeClaimTemplate:
33. spec:
34. storageClassName: ebs-sc
35. accessModes: ["ReadWriteOnce"]
36. resources:
37. requests:
38. storage: 10Gi. grafana.enabled: true
prometheusスタック Helmチャートで視覚化ソリューション Grafanaまでも追加設定なく一回でインストールできます。
. grafana.ingress
AWS LB & External DNS Controllerで Ingressの構成が可能です。
. ingress.annotations.
alb.ingress.kubernetes.io/scheme: internet-facing # or internal
VPN設定の運用環境では VPC内部だけでアクセス可能とするinternalへ変更します。或いはSecurity Groupを設定して許可されたIP帯域のみ接続できるように設定できます。
. prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues: false
他のHelmチャートで定義したServiceMonitorカスタムリソース(CR、Custom Resource)を使用できるようにします。
. prometheus.prometheusSpec.retention
メトリクスデータの保存期限を指定します。筆者はテスト環境のため、5日 (5d)を指定しました。状況により 1ヶ月、6ヶ月等に変更します。
. prometheus.prometheusSpec.retentionSize
ストレージ容量を指定します。 PVC拡張が可能なため、実際の使用量で変更できます。上記のようにデフォルトインストールオプションに簡単な設定の変更をしただけで、初期の運用環境に適用可能なモニタリングシステムの構築ができます。勿論、実際の環境では多くの追加作業が必要ですが、初期段階では問題のないシステムを構築できます。
では、インストールを行います。
1. (jerry-test:kubecost)kube-prometheus-stack-48.3.1$ k ns monitoring
2. (jerry-test:monitoring)kube-prometheus-stack-48.3.1$ helm install prometheus -f ci/my-values.yaml .
3. NAME: prometheus
4. LAST DEPLOYED: Sat Nov 4 13:59:39 2023
5. NAMESPACE: monitoring
6. STATUS: deployed
7. REVISION: 1
8. NOTES:
9. kube-prometheus-stack has been installed. Check its status by running:
10. kubectl --namespace monitoring get pods -l "release=prometheus"
11.
12. Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.正常にインストールが完了すると、次の Podが実行されます。
1. (jerry-test:monitoring)~$ k get pod
2. NAME READY STATUS RESTARTS AGE
3. alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 16h
4. prometheus-grafana-7cbdbd5c47-4rrw4 3/3 Running 0 16h
5. prometheus-kube-prometheus-operator-795b9759b8-t8pbs 1/1 Running 0 16h
6. prometheus-kube-state-metrics-6df4697c45-n9b67 1/1 Running 0 16h
7. prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 16h
8. prometheus-prometheus-node-exporter-rnwsz 1/1 Running 1 (16h ago) 16h
9. prometheus-prometheus-node-exporter-w2vpl 1/1 Running 0 16各Podを確認します。
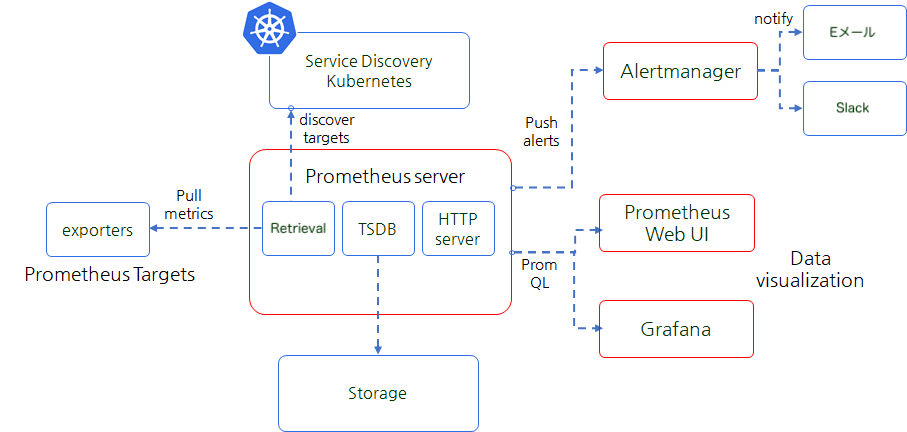
- アラートマネージャー(alertmanager)
prometheusは事前に定義したポリシー基盤(例:ノードのダウンロード、Pod Pendingなど)にシステムアラートメッセージを生成します。メッセージはアラートマネージャーで発生させて、重複メッセージの削除、メッセージのグループ化や抑制等の事後処理後に、指定されたEメール、Slack等のアラート発生チャネルに転送します。
- Grafana(grafana)
prometheusはメトリクス情報を保存用に使用して、その情報の照会はprometheusでは基本的なグラフ形態でのみ可能です。多様なグラフとチャートで見たい場合は別途の視覚化ソリューションGrafanaがあります。Grafanaはメトリクス情報を prometheusと同様にPromQL(Prometheus Query Language)検索言語で照会できます。
- prometheus Pod(prometheus-0)
prometheus Podはstatefulsetで配布されます。モニタリング対象になる Podはexporterという別の Sidecarパターンのコンテナーで、モニタリング対象になるメトリクスを発生させます。prometheus PodはメトリクスをPull方式で収集し、内部の時系列データベース(TSDB、Time Series DataBase)に保存します。保存された情報をprometheus WebサーバまたはGrafanaで、グラフ形態で照会します。システムアラート(alert)はアラートマネージャーが発生させます。
- ノードエキスパート(node-exporter)
ノードエキスパートは、デーモンセットでインストールされ、モニタリング対象になる全体ノードに自動でインストールされ、物理ノードのリソース使用量(ネットワーク、ストレージ等)の情報をメトリクス形態に変換して発生させます。
上記の必須構成要素以外に prometheus Helmチャートは次の Podを追加でインストールします。
- prometheusオペレータ(prometheus-operator)
システムアラートメッセージポリシー (prometheus rule)、アプリケーションモニタリング対象の追加(ServiceMonitor)等の作業を便利にするカスタムリソースをサポートします。
- kube-state-metrics
名前から分かるようにクバネティスの状態(kube-state)をメトリクスに変換するPodです。クバネティスAPIサーバと通信して各オブジェクトの状態をメトリクス形態に変換して prometheusが収集できるようにします。コントロールプレーンノードのアプリケーションの状態、クバネティスリソースリストの状況等のクラスター全般の状況を確認できます。既存のVM環境とは異なる部分です。
Prometheusは2つのカスタムリソースを使用します。アプリケーションモニタリング対象は ServiceMonitor、アラート設定は PrometheusRulesです。
1. (jerry-test:default)~$ k get servicemonitors.monitoring.coreos.com -A
2. NAMESPACE NAME AGE
3. monitoring prometheus-grafana 4d11h
4. monitoring prometheus-kube-prometheus-alertmanager 4d11h
5. monitoring prometheus-kube-prometheus-apiserver 4d11h
6.
7. (jerry-test:default)~$ k get prometheusrules.monitoring.coreos.com -n monitoring
8. NAME AGE
9. prometheus-kube-prometheus-alertmanager.rules 4d11h
10. prometheus-kube-prometheus-config-reloaders 4d11h
11. prometheus-kube-prometheus-etcd 4d11h
12. (省略)ServiceMonitorは Prometheus Operatorと同時に使用するカスタムリソースです。このリソースは Prometheusがクバネティスサービスをどのように発見してスクレイピング(Scraping)するかを定義します。 ServiceMonitorは特定のサービスのメトリクスを収集する方法と周期、ポート、パス等を指定します。 Prometheus OperatorはServiceMonitorリソースで、自動でPrometheusのスクレイピングの設定をし、指定されたサービスでメトリクスを収集します。これにより、ユーザは手動でPrometheusの設定をする必要がなく、クバネティス内でメトリクスの収集を効率的に管理できます。
今後の運用で、アプリケーションのモニタリング設定を追加する場合、上記2つのリソース変更事項を確認します。
このような全体構成を簡単に図で表すと、次の通りになります。
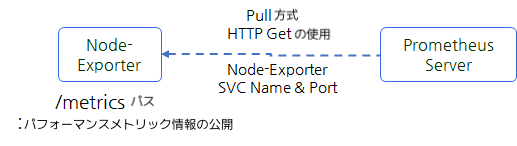
3. Node-Exporterのアーキテクチャーの確認
では、 Prometheusがどのように Pull方式でエージェントのメトリクス情報を収集しているかNode-Exporterで確認します。port-forwardingで node-exporter Podに接続します。
1. (jerry-test:monitoring)~$ k port-forward svc/prometheus-prometheus-node-exporter 9100:9100
2. Forwarding from 127.0.0.1:9100 -> 9100
3. Forwarding from [::1]:9100 -> 9100下記のスクリーンキャップチャーで確認できるようにnode-exporterの ‘/metrics’ディレクトリに接続すると、モニタリング関連メトリクスを確認できます。下記は筆者が‘cpu’で検索した内容でCPU使用率関連のメトリクスの照会が確認できます。
このようにNode-Exporterが提供するメトリクスを PrometheusがPull方式で収集し、Prometheus独自の時系列ストレージに関連情報を保存します。
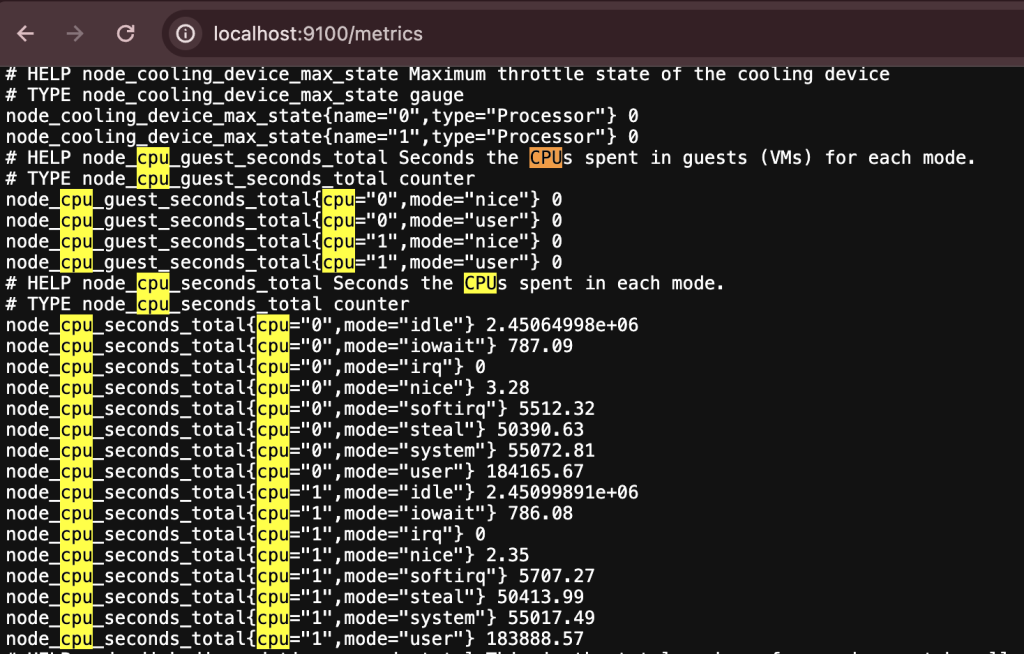
サービスの運用中、特定メトリクスの有無の確認が必要であれば、上記のようにメトリクスを発生するアプリケーションの Exporterでメトリクスが存在するかを直接確認できます。
次は、同じく port-forwardを利用して Prometheus UIへ接続します。
1. (jerry-test:monitoring)~$ k port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090
2. Forwarding from 127.0.0.1:9090 -> 9090
3. Forwarding from [::1]:9090 -> 9090Graphメニューに node_cpu関連メトリクスを照会すると、下記の様に照会できます。 node-exporterが提供するメトリクス関連情報を正常に取り込んで保存し、メトリクスを照会できます。
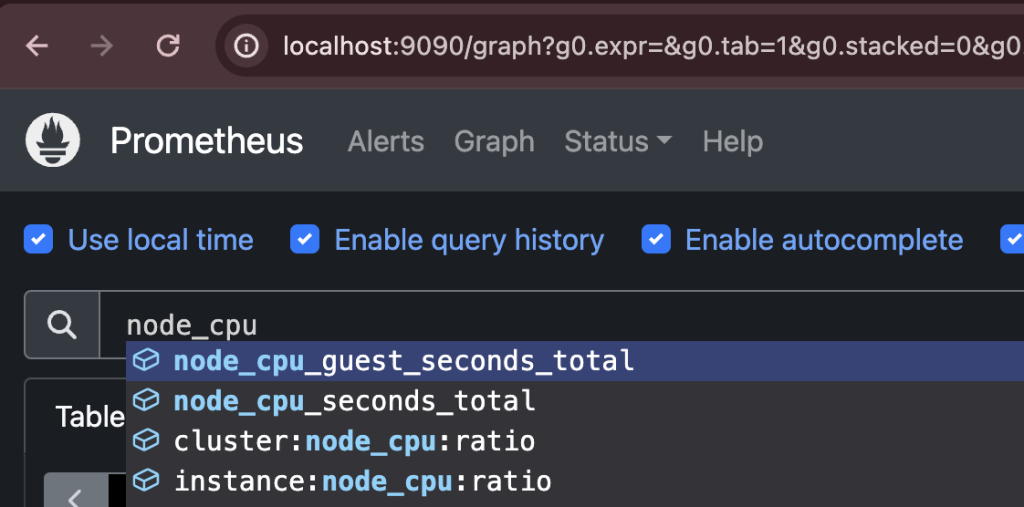
簡単に図に表すと次の通りです。
4. prometheusアドミンページ
次は、prometheusアドミンページを確認します。 Prometheusに接続すると次のような上段のメニューを確認できます。
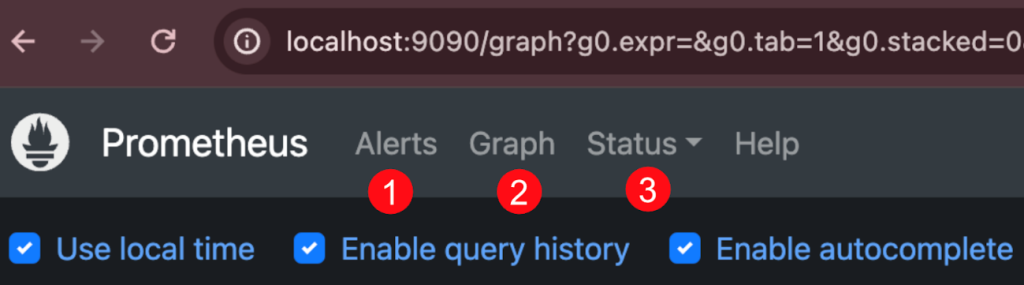
主なメニューを以下に簡単に説明します。
① アラート(Alerts)
事前に定義したシステムアラートポリシー(Prometheus Rules)の状況を表します。システムアラートメッセージを確認する場合、このページを利用します。アラートの詳細な設定は次回に説明します。
② グラフ(Graph)
prometheusの独自検索言語 PromQLでメトリクス情報をグラフで照会できます。 Prometheusは単純なグラフだけをサポートしていますが、多様な視覚化効果のあるグラフではGrafanaを使用します。単純なメトリクス確認で使用します。
③ 状態(Status)
アラートメッセージポリシー (Rules)、モニタリング対象(Targets)等の多様な prometheusの設定内容を確認できます。
次に主なメニューの詳細を確認します。
DevOps、インフラ管理者が注意して確認して欲しいメニューは主に 3番目の状態(Status)です。事例で Status – Targetsメニューを選択します。
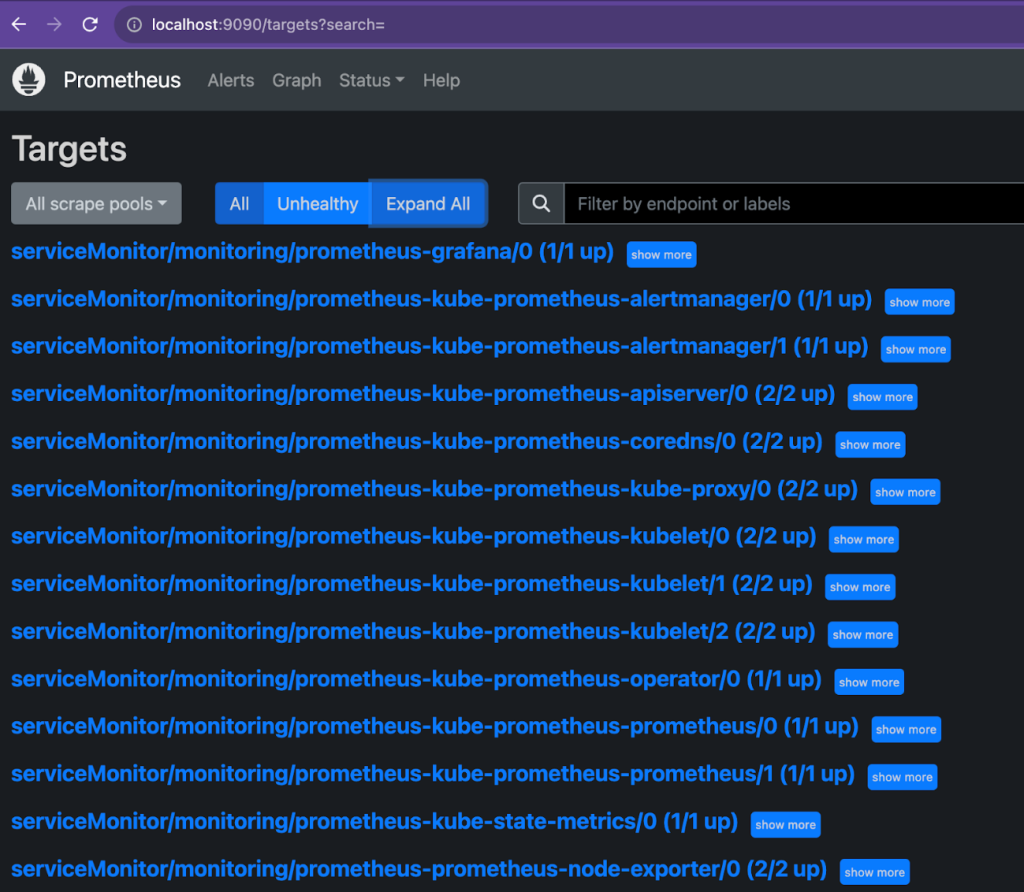
前に照会したServiceMonitorカスタムリソースリストを確認できます。
1. (jerry-test:default)~$ k get servicemonitors.monitoring.coreos.com -A
2. NAMESPACE NAME AGE
3. monitoring prometheus-grafana 4d11hメトリクスが正しくモニタリングされると、上記のように up状態で問題があればdownに表示されます。特定アプリケーションのモニタリングクエリ(PromQL)が実行できない時に、最初に確認すべき部分の一つです。
次に、 Status – Command-Line Flagsを確認すると、Helmインストール時に登録したValues設定を確認できます。

Helm Valuesファイルで設定した複数の設定が、実際に反映した状態を確認できます。初期設定で簡単にストレージ容量 ‘10GiB’、ストレージ保存期限 ‘5d’ 等を設定しましたが、実際反映されたことを確認できます。
その他 prometheus運用関連バージョン、scrape_interval(モニタリング周期)、scrape_timeoutなど複数の設定情報がRuntime & Build Information、Configurationメニューで確認できます。必要により確認し、変更してください。
では、実運用環境でアプリケーションモニタリングを追加する事例を確認します。特定アプリケーションを追加して、そのアプリケーションの状態を確認するために、モニタリングを登録することは運用中によくある作業です。この作業はPrometheusでは Exporterリソースで効果的に利用されます。
大半のアプリケーションはHelmチャートにモニタリング関連 Exporter部分が含まれています。このオプションを Enableにして比較的簡単にprometheusにモニタリングエージェントを登録できます。 Prometheusがモニタリングの標準ソリューションで使用されることは大きなメリットです。
では、前にインストールしたRedis事例で確認します。Redis Helmチャートの Values.yamlファイルです。このファイルは Githubで確認できます。
1. architecture: replication
2. auth:
3. enabled: false
4. master:
5. count: 1
6. replica:
7. replicaCount: 2
8. sentinel:
9. enabled: false
10. metrics:
11. enabled: true
12. serviceMonitor:
13. enabled: true ## serviceMonitor - Exporter登録
14. prometheusRule:
15. enabled: true ## アラートRule登録
16. sysctl:
17. enabled: true. metrics.enabled
prometheusがモニタリングできるようにRedis Exporter設定を登録します。 Prometheusは Exporterを使用してメトリクスをモニタリングします。 Exporterはシステム、サービスのメトリクスを収集し、 Prometheusが処理できる形式に変換するツールで、多様なソースで収集されたメトリクスを統合的にモニタリングできます。多様なシステムとアプリケーションで生成されたメトリクスを Prometheusの標準形式に変換します。Exporterは収集されたメトリクスを Prometheusがスクレイピングできる HTTPエンドポイントに露出します。
. metrics.serviceMonitor.enabled
serviceMonitor カスタマイズリソースに登録して prometheusのリソース再開をしないでモニタリング対象に登録します。
. metrics.prometheusRule.enabled
アラートルールで登録します。
モニタリング設定を含めてRedis Helmチャートを配布します。インストール後にPodの数を確認すると下記の様に2個です。
1. (jerry-test:redis)~$ k get pod
2. NAME READY STATUS RESTARTS AGE
3. redis-master-0 2/2 Running 0 4d11h
4. redis-replicas-0 2/2 Running 0 4d11h
5. redis-replicas-1 2/2 Running 0 4d11h設定を確認すると、モニタリング関連 Exporter PodがSidecarパターンで追加実行中であることが確認できます。
1. (jerry-test:redis)~$ k describe pod redis-master-0
2. (中略)
3. Containers:
4. redis:
5. Container ID: containerd://b41aedc6ab5a8d72b7afec0691c3cf5cbf7115a26e4cfad40f46fe3aed5d307d
6. Image: docker.io/bitnami/redis:7.0.9-debian-11-r1
7. Image ID: docker.io/bitnami/redis@sha256:57e071d75ab5eff3dcafd53107f256e1a2b41eeb52eddc73395487ebf83fa257
8. (中略)
9. metrics:
10. Container ID: containerd://3886b68cb873cc2b912f2f92001647193cba2ce2a3d1d05bfcb5a459f66f9075
11. Image: docker.io/bitnami/redis-exporter:1.47.0-debian-11-r1
12. Image ID: docker.io/bitnami/redis-exporter@sha256:dd009d59117afcefc277f66a5f189ab9ec6e7b490245241b7b6efc9b5a46279c
13. Port: 9121/TCPredis Pod以外にmetrics Podがredis-exporterで実行中です。このように互いにイメージを分離してモニタリング設定を追加する場合でも、既存のイメージを変更なく(イメージ不変の原則)、新しい exporterイメージを追加する形態で運用します。Exporter Sidecarイメージを利用して prometheusにエージェントが登録されます。
設定が完了するとRedisと関連するServiceMonitor、PrometheusRulesリソースを確認できます。
1. (jerry-test:redis)~$ k get servicemonitors.monitoring.coreos.com
2. kNAME AGE
3. redis 4d11h
4. (jerry-test:redis)~$ k get prometheusrules.monitoring.coreos.com
5. NAME AGE
6. redis 4d11hこれで、Redisアプリケーションがモニタリング対象として正常に登録が完了し、次回に確認予定のダッシュボードにメトリクスを利用して Redisアプリケーションモニタリングの設定を完成できます。
このように Helm設定にモニタリングオプションを追加するだけで、簡単にアプリケーションモニタリング設定を進めることができます。
以上で今回は Prometheusについて確認しました。 Prometheusの強力なモニタリング機能と拡張性は現代ITインフラ管理に必須です。単純にデータを収集して表示することを超えて、システムの性能を最適化し、潜在的な問題を事前に予防する時に重要な役割を果たします。我々がPrometheusから得た能力は、IT環境が直面する継続的な挑戦を克服する時に重要な自信になります。
- CNCF 2番目の卒業プロジェクト : https://www.cncf.io/announcements/2018/08/09/prometheus-graduates/
- SoundCloudで始まったPrometheusプロジェクト : https://prometheus.io/docs/introduction/overview/
- ログ、トレーシングは次回で説明します。
- Kube-Prometheus-Stack Helmチャート : https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
- アラートマネージャーの役割: https://prometheus.io/docs/alerting/latest/alertmanager/
- kube-state-metrics: https://github.com/kubernetes/kube-state-metrics